 Hadoop 基础原理
Hadoop 基础原理
Hadoop 是一个由 Apache 基金会开发的分布式系统基础架构,主要解决海量数据的存储和计算问题,广义上 Hadoop 指的是 Hadoop 生态圈,包含 HDFS、Hive、MapReduce、HBase 多种组件
# 基本介绍
# Hadoop 的必要性
Hadoop 主要解决了海量数据的存储问题
- 高可用性:底层会维护多个数据副本,所以即使 Hadoop 某个计算元素或存储出现故障,也不会导致数据的丢失
- 高扩展性: 在集群间分配任务数据,可方便的扩展数以千计的节点
- 高效性: 在 MapReduce 的思想下,Hadoop 是并行工作的,以加快任务处理速度。
- 高容错性: 能够自动将失败的任务重新分配
一个 block 块在 NameNode 中占150byte(固定),过多小文件会占用 NameNode 内存 小文件的寻址时间大于读取时间 不支持并发写和随机写 一个文件只能有一个写,不允许多线程同时写
# Hadoop 核心组件
Hadoop 核心组件包含以下两种
- HDFS:是 Hadoop 的分布式文件系统,主要负责海量数据的存储
- MapReduce:是 Hadoop 的计算框架,负责对数据进行分布式计算处理。处理流程分为 Map 阶段(并行处理输入数据,将数据转换为键值对)和 Reduce 阶段(对 Map 阶段的结果进行汇总和进一步处理)
# Hadoop 生态系统中的附加组件
我们后端开发接触的比较多的是Hadoop 生态系统中的附加组件,Sqoop 以及 Hive,分别用来同步数据和查询数据
- Sqoop:Hadoop(Hive)与传统数据库(Mysql)之间传输数据的工具,支持批量导入和导出数据
- Flume 高可用、高可靠分布式的海量日志采集、聚合和传输系统
- Spark:是一个通用的分布式计算框架,支持内存计算,可以显著提高数据处理速度。它支持多种计算模式,包括批处理、流处理、机器学习等
- HBase:HBase 是一个分布式的、面向列的 NoSQL 数据库,建立在 HDFS 之上。它提供了实时读写访问,适合处理大规模数据集
- Hive:是基于 Hadoop 的数据仓库工具,它提供了一种 SQL-like 的查询语言(HiveQL),使用户可以方便地进行数据查询和分析。它可以将 HiveQL 转换为 MapReduce 任务执行
# 基础特性
hive 表可以通过 Hive/Spark/Impala 等计算引擎生成
- Hive:将 SQL 翻译成 MapReduce 任务,适合高延迟、高吞吐的批处理
- Spark:基于内存计算,兼顾批处理、流处理、机器学习等多种场景,性能远超传统 MapReduce
- Impala:专为低延迟交互式 SQL 查询而生
HDFS 存放目录文件的格式是层级(树状)结构的,这是 HDFS 为了实现数据分布、并行处理和高效查询而设计的分区化层级结构。
# HDFS
HDFS 是 Hadoop 的分布式文件系统,解决了海量数据的存储问题
# HDFS 集群架构
HDFS 使用 Master/Slave 架构,架构逻辑比较类似 Kafka、ES 等 Apache 的其他项目
一般一个集群有一个 NameNode 和一定数目 DataNode 组成,Namenode 是 HDFS 集群主节点,Datanode 是 HDFS 集群从节点,两种角色各司其职,共同协调完成分布式的文件存储服务
HDFS 中文件在物理上是分块存储,通过 dfs.blocksize 配置,2.x之后的版本默认128M
HDFS 中文件在逻辑上是连续的,提供一个文件目录树
# HDFS 读写流程
# HDFS 写流程
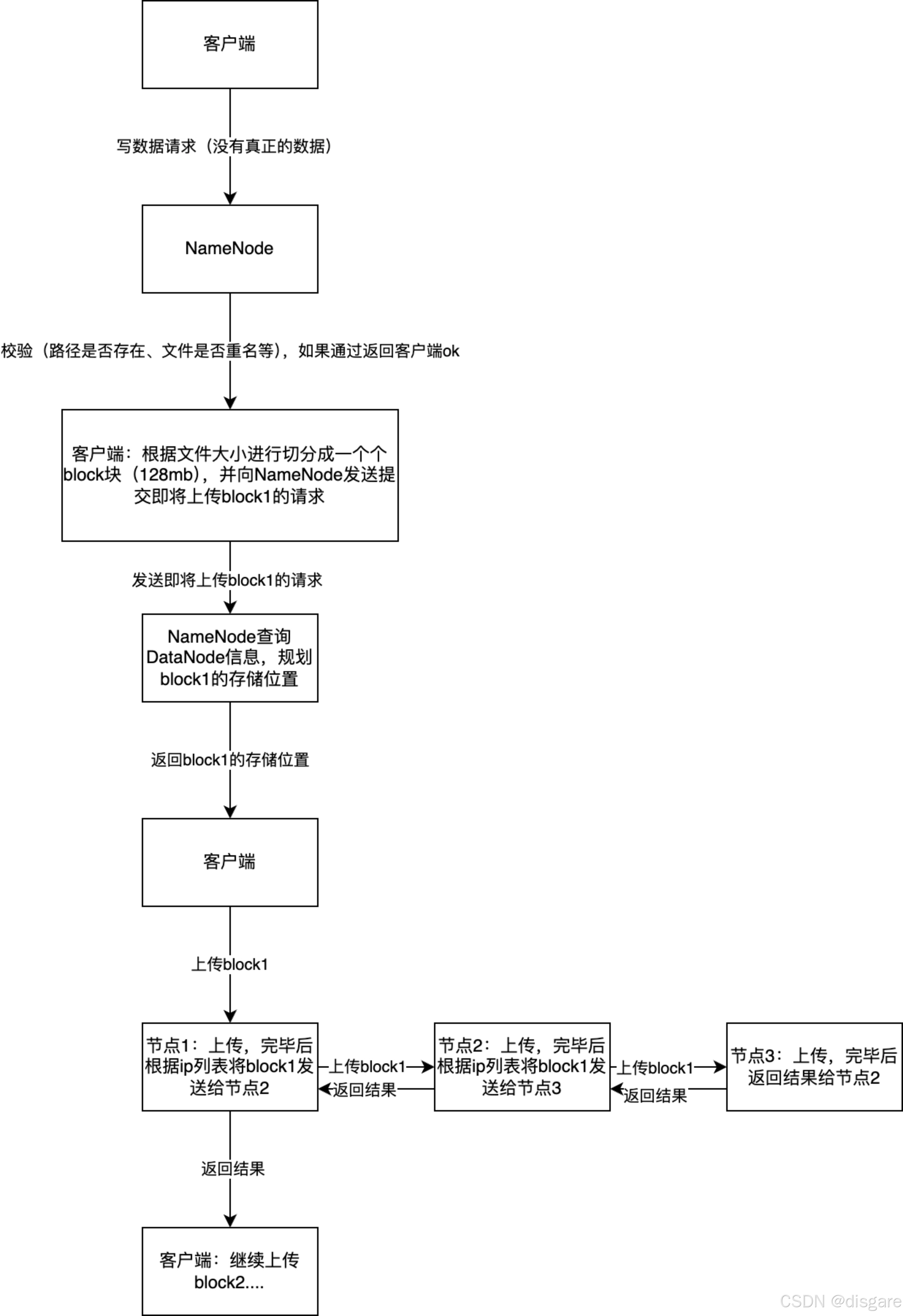
1,客户端向 NameNode 发送写数据请求(包含待上传文件名和将要上传的路径)
2,NameNode 检查路径是否存在,文件是否重名等(假设满足上传条件)
3,NameNode 向客户端响应数据,可以上传文件,并且创建文件元数据
4,客户端根据文件大小进行切分成一个个 block 块(默认128MB),并向 NameNode 发送提交即将上传 block1 的请求
5,NameNode 查询 DataNode 信息,规划 block1 的存储位置
6,NameNode 向客户端返回 block1 可以存储的数据节点 ip 列表
7,客户端直接请求数据节点1上传 block1,数据节点1存储 block1 完毕并根据 ip 列表将 block1 发送给数据节点2,数据节点2存储完毕 block1 并根据 ip 列表将 block1 发送给数据节点3,数据节点3存储完成响应数据给数据节点2,数据节点2将响应数据给数据节点1,数据节点1将存储结果返回给 NameNode 和客户端
9,重复第四步上传下一个block
 我知道你们想问什么,为什么 HDFS 的写流程必须一个个的上传块,不能并发上传吗?这是设计者对于 HDFS 写少读多场景的这种考量。该场景如此设计的好处:
我知道你们想问什么,为什么 HDFS 的写流程必须一个个的上传块,不能并发上传吗?这是设计者对于 HDFS 写少读多场景的这种考量。该场景如此设计的好处:
1,每个数据块的写入是原子操作,即要么成功写入,要么完全不写入,这确保了数据的一致性。如果并发写入需要额外考量并发安全性问题 2,管道复制机制保证了传输的效率,我们针对每个上传的文件其实是并发上传的,这样就够了,实际测下来没有必要对每个文件的多个 block 并发上传 3,同时维护多个 block 传输需要大量内存和网络带宽
为什么一定要用管道复制机制?
1,带宽高效利用,数据沿管道顺序流动:客户端 → DN1 → DN2 → DN3。每个节点同时进行接收和发送,相比客户端分别上传到各 DN,节省约2/3的上传时间。由于管道的存在缓冲区可以占用较少的内存空间
2,降低客户端负载,客户端只需连接第一个 DataNode,不直接与所有副本节点通信(减少连接数和带宽占用),特别有利于大文件上传(避免客户端成为瓶颈)

# HDFS 读流程
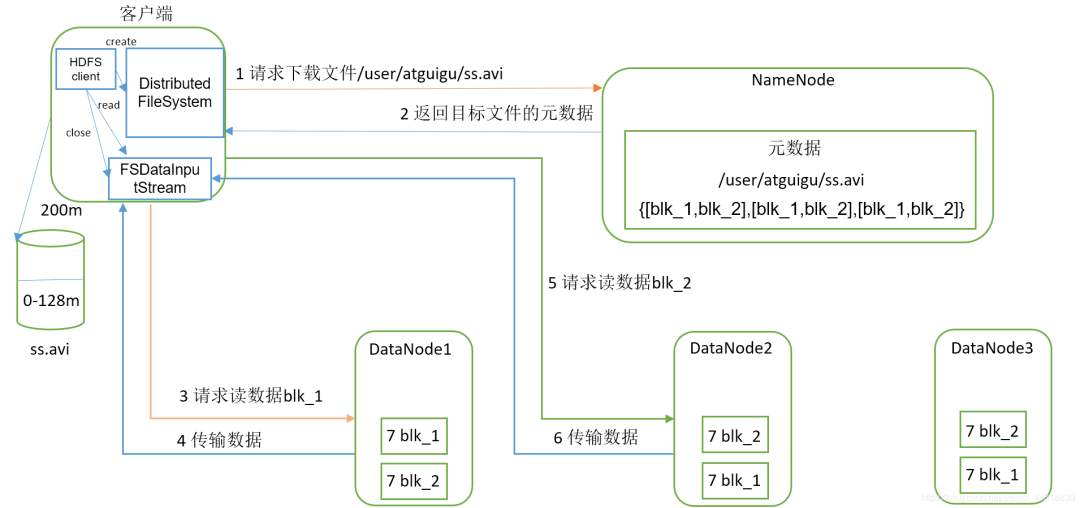
1,客户端向 NameNode 请求下载文件
2,NameNode 返回目标文件的元数据
3,客户端根据元数据请求 DataNode 读取数据 block
4,DataNode 向客户端传输数据
5,重复第三步,直到所有的块传输完成
6,客户端根据元数据组装 block 块完成读取数据
# NameNode 和 DataNode
NameNode 是名称节点,核心职责是管理文件系统的元数据(文件名、记录每个 block 所在的 DataNode 位置、block 列表等),并且协调客户端访问
NameNode 不存储实际数据,所有元数据存储在内存中(因此限制集群规模)
NameNode 在早期是单点架构的,很容易出问题,因此 HDFS 2.0 后支持 HA,就是高可用方案
[Active NameNode] ←→ [JournalNodes] ←→ [Standby NameNode]
↑ ↑ ↑
(客户端请求) (共享编辑日志) (实时同步)
2
3
- JournalNodes 用于存储编辑日志(Edits),实现主备 NameNode 的元数据同步,他可以保证故障切换时不丢失数据
- ZooKeeper:负责故障检测和主备切换
DataNode(数据节点),核心职责为实际存储数据 block,定期向 NameNode 汇报存储情况,也就是心跳检测,默认每个 block 有3个副本(可配置)
HDFS 会定期校验数据完整性
# NameNode 持久化机制
NameNode 元数据的存储位置是在内存中,但是内存一旦断电元数据将丢失,因此必须将内存中的元数据存储在磁盘中用于备份,这里引入额外一个概念叫 Fsimagem
Fsimagem 为内存元数据的备份。若内存的元数据发生改变,如果同时更新 Fsimage 会降低效率,如果不更新会发生数据不一致问题
针对上述问题,最终逻辑是不更新 Fsimage 文件,为解决数据不一致问题,引入 edits 文件,该文件只记录操作并且采用追加写的形式,即每当内存的元数据发生改变的同时记录本次操作记录追加到磁盘中的 edits,这样内存元数据等于磁盘的 Fsimage + edits
当 NameNode 启动时先滚动 edits 并生成一个空的 edits.inprogress,会将 Fsimage 和 edits 文件加载到内存中进行合并,之后的操作(增删)将追加到 edits.inprogress 中
其行为类似 redis 的 RDB 和 AOF 机制,MySQL 中的 binlog 和 redolog,这些数据存储的软件持久化实现都差不多
# hdfs 数据倾斜怎么处理
一般业务研发不用处理这个问题,还是简单聊一下吧,数据倾斜通常指 DataNode 负载不均,原因可能是:
- 写入模式问题:若客户端总往同一 DataNode 写数据(比如日志集中写入),会导致该节点数据过多
- 节点容量差异:新加入的大容量节点可能分配到更多数据,旧节点负载轻
- 副本策略影响:HDFS 默认将副本分散到不同机架,但如果机架间网络延迟高,可能导致副本集中
处理方式就是 hdfs balancer,他是 HDFS 自带的集群平衡工具,原理如下:
- 先计算所有 DataNode 的存储利用率,对比各节点利用率,找出超过平均阈值(默认 10%)的节点
- 将高负载节点的数据块(Block)复制到低负载节点,完成后删除原副本
# MapReduce
MapReduce 是一种编程模型和分布式计算框架,是开发基于 Hadoop 的数据分析应用的核心框架。MapReduce 的主要用途包括:
- 大数据处理:处理和分析 PB 级别的数据,如日志分析、数据挖掘、统计分析等
- 数据转换:将原始数据转换为所需的格式,如 ETL(Extract, Transform, Load)任务
- 数据索引:构建大规模数据的索引,如搜索引擎的网页索引
- 机器学习:处理大规模的训练数据,进行模型训练和预测
总之,只要是统计或者计算 Hadoop 中的数据,都会用到 MapReduce。Hive(基于 Hadoop 的数据仓库工具,它提供了一种 SQL-like 的查询语言,使得用户可以方便地进行数据查询和分析)底层对接 MapReduce 来执行查询和数据处理任务。Hive 的查询最终会被转换成一个或多个 MapReduce 作业来执行
# 底层原理
MapReduce 实现分布式计算分成3个阶段,Map(映射)、Shuffle(洗牌)、Reduce(归约)
先从 HDFS 中找到要处理的数据作为输入数据,输入数据被 HDFS 切成多个小块(一般是 128MB 一块),每个小块称为一个切片(split),每个块由一个 Map 任务处理,准确的说是 MapTask 并发实例,他们完全并行运行,互不干扰
接下来进入 map 阶段,map 是第一个阶段。Map 任务会读取数据块,对每条记录调用用户定义的 Map 函数,生成中间键值对,进行排序并分区的操作(如按 Key 的哈希值分到不同 Reducer)
相同类型的数据被分到一块,随后我们对数据进行处理,进入第二个阶段,执行 ReduceTask,这一阶段也是完全并行运行,数据依赖上一个阶段所有 MapTask 并发实例输出。将 Map 任务生成的中间键值对进行分区、排序和合并等操作
- 分区(Partitioning):根据键的哈希值将中间键值对分配到不同的 Reduce 任务中
- 排序(Sorting):对每个分区内的键值对按键进行排序
- 合并(Merging):将来自不同 Map 任务的相同键的键值对合并在一起
这些操作被称为 Shuffle(洗牌),Shuffle 完毕将多个结果合并,就是 reduce 操作,reduce 操作完成后就是最终结果了
MapReduce 编程模型只能包含一个 Map 阶段一个 Reduce 阶段,但可以实现多个 MapReduce 串行运行
# 示例
上面的描述可能有些抽象,让大家有很多问题,比如为啥 ReduceTask 也可以并行执行?如果 MapTask 的产物是键值对的话,那么存放在 HDFS 的关系型表会怎么转换成键值对然后暴露给我们?接下来举个例子让大家更加深入的了解问题:
假设我们有一个关系型表 users,其结构如下:
| user_id | name | age | city |
|---|---|---|---|
| 1 | Alice | 25 | New York |
| 2 | Bob | 30 | London |
| 3 | Carol | 22 | New York |
| 4 | Dave | 28 | Tokyo |
假设我们要计算每个城市的用户数量:
SELECT city, COUNT(*) AS user_count
FROM users
GROUP BY city;
2
3
在这个例子中,Map 阶段会将每行数据转换为键值对,其中键是城市名称,值是用户 ID。例如:
- 输入行:1, Alice, 25, New York。输出键值对:(New York, 1)
- 输入行:2, Bob, 30, London。输出键值对:(London, 2)
- 输入行:3, Carol, 22, Paris。输出键值对:(New York, 3)
- 输入行:4, Dave, 28, Tokyo。输出键值对:(Tokyo, 4)
Map 阶段结束我们就得到很多键值对,在 Reduce 阶段,Hive 会将 Map 任务生成的中间结果按键进行分组,相同城市的键值对会被分到一个 ReduceTask 中:
- (New York, [1,3]) -> (New York, 2)
- (London, [2]) -> (London, 1)
- (Tokyo, [4]) -> (Tokyo, 1)
ReduceTask 输出最后的处理结果。所以一个 sql 在 Hive 中的执行流程和普通 db 中是完全不一样的。通过上面的 case 我们可以看出,先 map 后 reduce 事实上就是想利用并发的能力处理大量数据,Hadoop 的创作者们将我们所有的查询操作都抽象成了这完全可以并行执行的两步