 Linux 中 JVM 常用工具以及常见问题解决思路
Linux 中 JVM 常用工具以及常见问题解决思路
# JVM 调优
正常来说我们一般不会接触到 JVM 调优,一般也不会出现 OOM 问题(就算出现了也大概率不是我们业务代码的问题,而是框架或者工具的问题),不过我们需要看 gc 日志来判断虚拟机的性能怎么样,以优化业务代码
gc 日志主要包含的信息为收集类型(是老年代还是新生代等)、从开始的多少 K 收集到了多少 K、收集的耗时是多少等数据,我们还可以观察 GC 日志的频率看看是否出现了短时间内出现了大量的收集行为。尽量让日志中不要出现 Full GC,因为会 STW,非常影响性能
# JVM 分析命令
除了 gc 日志,一般来说,我们分析会用到以下的命令:
# jstack 分析栈情况
jstack:主要用来查看某个 Java 进程内的线程栈信息,根据堆栈信息我们可以定位到具体代码,具体用法需要先找到线程
第一步先找出 Java 进程 ID,我部署在服务器上的 Java 应用名称为 mrf-center。这里也可以用 top 命令找
root@ubuntu:/## ps -ef | grep mrf-center
root 21711 1 1 14:47 pts/3 00:02:10 java -jar mrf-center.jar
2
3
得出进程 ID 为21711,通过进程可以找到进程中的线程,以及线程执行时间、消耗 CPU 和内存资源情况,找出异常数据,通过线程 ID 配合 jstack,就可以输出进程21711的堆栈信息了。里面会包含在哪个类执行哪些方法
root@ubuntu:/## jstack 21711 | grep 54ee
"PollIntervalRetrySchedulerThread" prio=10 tid=0x00007f950043e000 nid=0x54ee in Object.wait() [0x00007f94c6eda000]
2
3
同时这个指令也可以看到有哪些线程在等待锁
jstack -l <pid> > thread_dump.txt
执行 jstack 需要切换自己的用户到之前执行 java 命令的用户,不然会报错
jstack 可以生成栈转储问题
# jstat 查看堆、gc 情况
jstat 是 JVM 统计监测工具,比如下面输出的是 GC 信息,采样时间间隔为 250ms,需要采样4次。通过这个命令可以看到大概发生了多少次 GC,以及平均 GC 耗时
jstat 命令命令格式:
jstat [Options] vmid [interval] [count]
参数说明:
- Options,选项,我们一般使用 -gcutil 查看 gc 情况
- vmid,VM 的进程号,即当前运行的 java 进程号
- interval,间隔时间,单位为秒或者毫秒
- count,打印次数,如果缺省则打印无数次
root@ubuntu:/## jstat -gc 21711 250 4
S0C S1C S0U S1U EC EU OC OU PC PU YGC YGCT FGC FGCT GCT
192.0 192.0 64.0 0.0 6144.0 1854.9 32000.0 4111.6 55296.0 25472.7 702 0.431 3 0.218 0.649
192.0 192.0 64.0 0.0 6144.0 1972.2 32000.0 4111.6 55296.0 25472.7 702 0.431 3 0.218 0.649
192.0 192.0 64.0 0.0 6144.0 1972.2 32000.0 4111.6 55296.0 25472.7 702 0.431 3 0.218 0.649
192.0 192.0 64.0 0.0 6144.0 2109.7 32000.0 4111.6 55296.0 25472.7 702 0.431 3 0.218 0.649
2
3
4
5
6
其对应的指标含义如下:
- S0C 年轻代中第一个 survivor(幸存区)的容量(字节)
- S1C 年轻代中第二个 survivor(幸存区)的容量(字节)
- S0U 年轻代中第一个 survivor(幸存区)目前已使用空间(字节)
- S1U 年轻代中第二个 survivor(幸存区)目前已使用空间(字节)
- EC 年轻代中 Eden(伊甸园)的容量(字节)
- EU 年轻代中 Eden(伊甸园)目前已使用空间(字节)
- OC Old 代的容量(字节)
- OU Old 代目前已使用空间(字节)
- MC 方法区大小
- MU 方法区目前已使用空间(字节)
- CCSC 压缩类空间大小
- CCSU 压缩类空间已使用大小
- YGC 从应用程序启动到采样时年轻代中 gc 次数
- YGCT 从应用程序启动到采样时年轻代中 gc 所用时间
- FGC 从应用程序启动到采样时 old 代 gc 次数
- FGCT 从应用程序启动到采样时 old 代 gc 所用时间
- GCT 从应用程序启动到采样时 gc 用的总时间
除此之外,我们还可以根据 top 或者 ps 命令,来查看是否有异常的线程占用了过多的 CPU 或者内存资源。使用 jmap 查看详细堆信息,或者打印 dump 日志
# jmap
jdk 安装后会自带一些小工具,jmap 命令 Java Memory Map 是其中之一。主要用于打印指定 Java 进程(或核心文件、远程调试服务器)的共享对象内存映射或堆内存细节
jmap 命令可以获得运行中的 jvm 的堆的快照,从而可以离线分析堆,以检查内存泄漏,检查一些严重影响性能的大对象的创建,检查系统中什么对象最多,各种对象所占内存的大小等等。可以使用 jmap 生成 Heap Dump。其用法如下
1,将数据导出:
jmap -dump:format=b,file=heap.bin <pid>
这个时候会在当前目录以生成一个 heap.bin 这个二进制文件
2,通过命令查看大对象
也是使用 jmap 的命令,只不过参数使用 -histo
jmap -histo <pid>|less
可得到如下包含对象序号、某个对象示例数、当前对象所占内存的大小、当前对象的全限定名,如下图
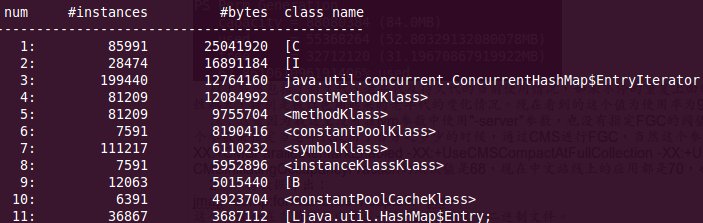 3,还可以查看对象数最多的对象,并按降序排序输出:
3,还可以查看对象数最多的对象,并按降序排序输出:
jmap -histo <pid>|sort -k 2 -g -r|less
4,查看占用内存最多的最象,并按降序排序输出:
jmap -histo <pid>|grep alibaba|sort -k 3 -g -r|less
# DUMP 日志内容
Dump 文件可以通过 jmap、jstack 命令生成,一般使用 MAT 工具分析
1,堆转储(Heap Dump),包含 Java 堆内存的完整快照:
- 所有对象信息:类实例、数组等
- 对象字段值:包括原始类型和引用
- 类信息:类名、修饰符、超类、接口等
- GC Roots:所有 GC 根对象引用链
- 对象大小:每个对象占用的内存大小
2,线程转储(Thread Dump),包含 JVM 中所有线程的状态信息:
- 线程列表:所有活动线程
- 线程状态:RUNNABLE、BLOCKED、WAITING、TIMED_WAITING 等
- 调用栈:每个线程的完整堆栈跟踪
- 锁信息:线程持有的锁和等待的锁
- 线程属性:名称、优先级、守护状态、线程组等
- 死锁检测:如果存在死锁会标识出来
3,核心转储(Core Dump),包含整个 JVM 进程的内存映像:
- 完整的进程内存:包括堆、栈、原生内存等
- 寄存器状态:CPU 寄存器内容
- 原生栈:本地方法调用的栈信息
- 共享库信息:加载的共享库状态
我在线上就遇到过,因为日志打的太多,导致内存缓冲区(它是内存空间的一部分。也就是说,在内存空间中预留了一定的存储空间,这些存储空间用来缓冲输入或输出的数据,Java 日志框架在将日志写入最终目的地之前,会使用缓冲区来提高性能)空间不足,观察 dump 日志后,发现堆转储中无用的 string 对象过多,观察日志发现,某个经常调用的方法中打印了一个巨大对象,最后将该日志删除解决问题,之前还发现过日志打太多导致的 OOM 问题
# 调优思路
由于调优会修改线上配置,影响较大,我们一般都是先找出哪里的代码写的有问题,实在没办法了,才会进行调优操作
一般修改的参数只有 xms 和 xmx,用于改动堆大小,不得不考虑进行 JVM 调优的是那些情况呢?
- Heap 内存(老年代)持续上涨达到设置的最大内存值;
- Full GC 次数频繁;
- GC 停顿时间过长(超过1秒);
- 应用出现 OutOfMemory 等内存异常;
- 应用中有使用本地缓存且占用大量内存空间;
- 系统吞吐量与响应性能不高或下降。
# 常见问题
# 内存泄漏
没有实际场景的 JVM 调优都是空谈,我们来看看如何定位内存泄漏问题
如果 gc 日志频繁的发生 fullGC,并且回收的内存逐渐变小,内存不足的话,我们就需要判断是否有内存泄漏问题了
我们可以先通过 jmap 查看堆内存
## jmap -heap pid
jmap -heap 27403
Attaching to process ID 27403, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.25-b02
using thread-local object allocation.
Mark Sweep Compact GC
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 1006632960 (960.0MB)
NewSize = 20971520 (20.0MB)
MaxNewSize = 335544320 (320.0MB)
OldSize = 41943040 (40.0MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
New Generation (Eden + 1 Survivor Space):
capacity = 216989696 (206.9375MB)
used = 116865984 (111.45208740234375MB)
free = 100123712 (95.48541259765625MB)
53.857849545077016% used
Eden Space:
capacity = 192937984 (184.0MB)
used = 116865984 (111.45208740234375MB)
free = 76072000 (72.54791259765625MB)
60.57178663170856% used
From Space:
capacity = 24051712 (22.9375MB)
used = 0 (0.0MB)
free = 24051712 (22.9375MB)
0.0% used
To Space:
capacity = 24051712 (22.9375MB)
used = 0 (0.0MB)
free = 24051712 (22.9375MB)
0.0% used
tenured generation:
capacity = 481370112 (459.0703125MB)
used = 288820968 (275.4411392211914MB)
free = 192549144 (183.6291732788086MB)
59.99977165179711% used
9569 interned Strings occupying 839416 bytes.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
如果发现老年代的对象越来越多,并且无法被回收,我们就基本可以定位到是内存泄漏的问题了,接下来使用 jmap -dump 导出 dump 文件,可以查看是哪个实例对象过多
一般来说,内存泄漏的情况包含:
- 使用 ThreadLocal 不当或者
- 将数据放进 map 时没有重写 equal 和 hashcode 方法的话,会出现内存泄漏问题
- 集合类中有对对象的引用,使用完后未清空
- 代码中存在死循环或循环产生过多重复的对象实体
# CPU 高
1,步骤:通过 top 命令查找进程-》查找线程(top 可以找出 CPU 占用最高的线程 ID)-》根据线程 ID 可以通过 jstack 命令定位问题代码-》找出问题代码
a、查看 cpu 高的 java 进程
top
b、生成进程下所有线程的栈日志。
jstack 1721 > 1712.txt
c、查看进程下哪些线程占用了高的 cpu
top -p 1712 -H
d、将十进制 pid 转换为十六进制的 pid
printf "%x" 8247
2037
2
3
e、在 1712.txt 文件中定位问题
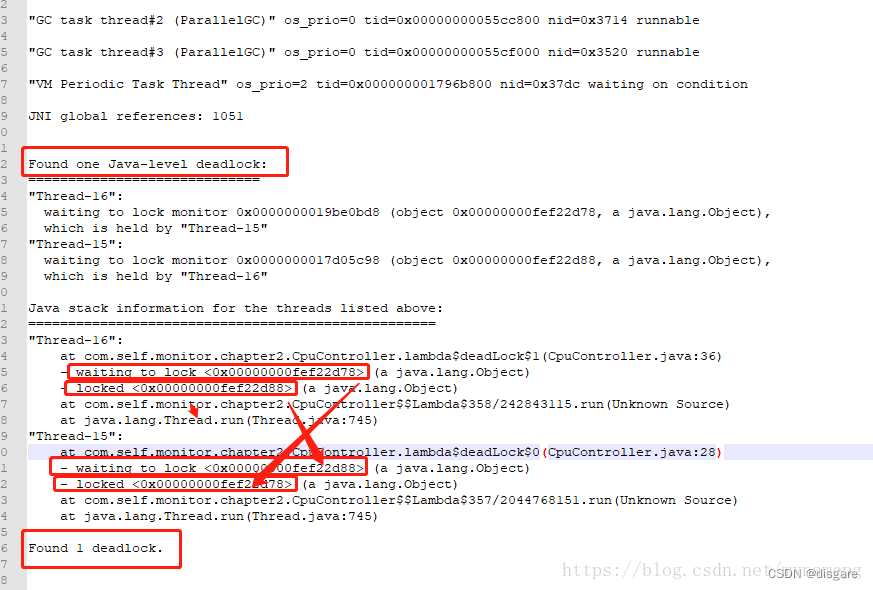
执行 jmap,jstack 等命令时可能会出现 Unable to open socket file: target process not responding or HotSpot VM not loaded 问题
其实大部分情况是用户错误,切换到进程所在用户执行命令即可
su yarn
# 系统平均负载高(load average)
平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数,它和 CPU 使用率并没有直接关系。一般来说单核 CPU 的 load 不应该大于1,同理,多核的 load 不应该大于核数
我们常见的负载高一般有这几种情况引起,一个是 cpu 密集型,使用大量 cpu 会导致平均负载升高。另外一个就是 io 密集型等待 I/O 会导致平均负载升高,但是 CPU 使用率不一定很高
还有就是大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高