 B+ 树的插入、删除和数据页分裂机制
B+ 树的插入、删除和数据页分裂机制
# 索引在磁盘中的存储
# 扇区
主存和磁盘之间的数据交换不是以字节为单位的,而是以n个扇区为单位的(一个扇区有512字节),通常是4KB(8个扇区),8KB(16个扇区),16KB,……64KB为单位的
一个扇区的内容物理上存放在一起,就像内存中的分页管理机制一样
# B+树比平衡二叉树、B树在磁盘中的优化
我们知道索引在磁盘中对应的是索引文件,并且一个 B+ 树的非叶节点中记录的数据不止2条,一般都会有100多条,而 B+ 树和平衡二叉树两者索引的速度几乎(甚至说就是)是一样的,那么 MySQL 为什么会选择 B+ 树呢
主要原因是 IO 效率底下,从磁盘到内存的主要查询消耗时间不在于查找,而在于 IO,B+树的优势在于可以在同一个储存单元存放尽可能多的指针记录以减少 IO 次数
如果这个 B+ 树存储到硬盘中,我们怎么根据记录的 key 找到对应的记录呢?首先我们要读取这个 B+ 树的根结点到内存(花费一个 IO 的时间)然后在内存中进行索引,根据 key 找到对应的分支,再将这个分支所指向的第二层索引结点读取到内存中(花费第二个 IO 时间)然后在内存中进行索引,同样根据 key 找到对应的分支,而这个分支指向的就是叶子结点,我们最后将这个叶子结点读取到内存中(花费的第三个 IO 时间)判断是否存在这个记录。这样我们只需要通过三次 IO 时间就从400万个记录中找到了对应的 key 记录,可以说是非常快了。想想平衡二叉树会进行多少次 IO
而 B+ 树比 B 树快速的原因也是这样,索引结点中不存数据,只存键和指针,所以一个索引结点就可以存储大量的分支,而一个索引结点只需要一次IO即可读取到内存中
# Innodb数据文件在磁盘中的储存
# 数据页
在 MySQL 的设定中,同一个表空间内的一组连续的数据页为一个 extent(区),默认区的大小为1MB,页的大小为16KB。16*64=1024,也就是说一个区里面会有64个连续的数据页。连续的256个数据区为一组数据区
其实不用在意数据区有什么用,比较重要的是数据页,它里面储存了数据和其他东西(比如上下数据页的指针、上下界),它长下面这样
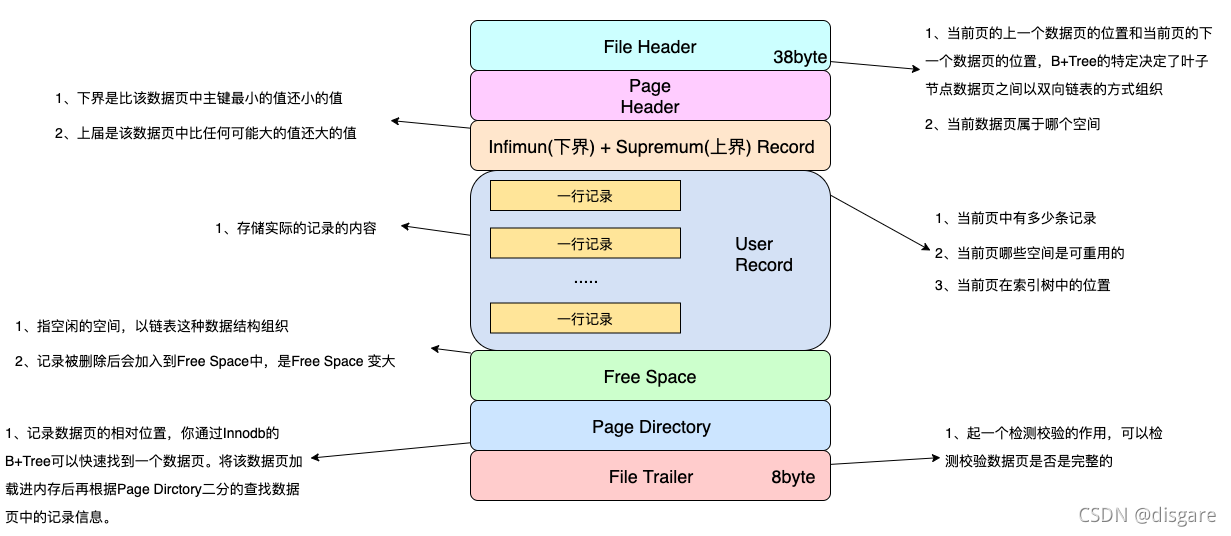
# 数据页分裂
总之数据页分裂就是保证了下一个数据页的所有记录都比这个数据页的最大记录要大
因为 innodb 中的所有数据文件都是索引文件,这样方便顺序查找
# 行溢出
当某一行数据过大,导致数据页存放不下时,我们把这种情况叫做行溢出
简单的解决方式就是把记录存储在溢出页(磁盘的其它空闲地方)中,然后叶子结点中存储的是这个记录的指针
# Innodb 中的 B+ 树如何处理重复 Key 的
b+树索引结构常采用溢出页处理重复出现的键值,这是类似 hashmap 中链表法解决 hash 冲突的办法
如果B+树出现了两个值相等的情况,那么B+树不会改变原有结构,也不会在叶子结点里面增加一项,而是将这个重复值作为一个新的节点,并用原本B+树上的节点的指针指向它
如果一行数据的基数为2(比如性别),在这一行创建索引还造成大量的溢出页,导致查询效率不增反降
# B树和B+树的添加删除算法
# B树的添加算法
1,根据要插入的key的值,找到叶子结点并插入,源码中使用二分查找
2,判断当前结点 key 的个数是否小于等于 m,若满足则结束,否则进行第3步
3,以结点中间的 key 为中心分裂成左右两部分,然后将这个中间的 key 发到到父结点中,这个 key 的左子树指向分裂后的左半部分,这个 key 的右子支指向分裂后的右半部分,然后将当前结点指向父结点,继续进行第3步
添加算法的关键在于,一个节点分裂成三个节点,并且父节点会向上插入
# B树的删除算法
1,如果当前需要删除的 key 位于非叶子结点上,则用后继 key(这里的后继 key 均指后继记录的意思)覆盖要删除的 key,然后在后继 key 所在的子支中删除该后继 key。此时后继 key 一定位于叶子结点上,这个过程和二叉搜索树删除结点的方式类似。删除这个记录后执行第2步
2,该结点 key 个数大于等于Math.ceil(m/2)-1,结束删除操作,否则执行第3步。
3,如果兄弟结点key个数大于Math.ceil(m/2)-1,则父结点中的key下移到该结点,兄弟结点中的一个key上移,删除操作结束
# B+树的添加算法
内部结点(也称索引结点)和叶子结点。根结点本身即可以是内部结点,也可以是叶子结点,同时,索引结点和叶子结点必须大小相同
对于内部结点中的一个key,左树中的所有key都小于它,右子树中的key都大于等于它
B+树的添加算法如下
1,若为空树,创建一个叶子结点,然后将记录插入其中,此时这个叶子结点也是根结点,插入操作结束。
2,针对叶子类型结点:根据key值找到叶子结点,向这个叶子结点插入记录。插入后,若当前结点key的个数小于等于m-1,则插入结束。否则将这个叶子结点分裂成左右两个叶子结点,左叶子结点包含前m/2个记录,右结点包含剩下的记录,将第m/2+1个记录的key进位到父结点中(父结点一定是索引类型结点),进位到父结点的key左孩子指针向左结点,右孩子指针向右结点。将当前结点的指针指向父结点,然后执行第3步。
3,索引类型结点的分裂算法和B树相同
# B+树的删除算法
1,删除叶子结点中对应的key。删除后若结点的key的个数大于等于Math.ceil(m-1)/2 – 1,删除操作结束,否则执行第2步。
2,若兄弟结点key有富余(大于Math.ceil(m-1)/2 – 1),向兄弟结点借一个记录,同时用借到的key替换父结(指当前结点和兄弟结点共同的父结点)点中的key,删除结束。否则执行第3步。
3,若兄弟结点中没有富余的key,则当前结点和兄弟结点合并成一个新的叶子结点,并删除父结点中的key(父结点中的这个key两边的孩子指针就变成了一个指针,正好指向这个新的叶子结点),将当前结点指向父结点(必为索引结点),执行第4步(第4步以后的操作和B树就完全一样了,主要是为了更新索引结点)。
4,若索引结点的key的个数大于等于Math.ceil(m-1)/2 – 1,则删除操作结束。否则执行第5步
5,若兄弟结点有富余,父结点key下移,兄弟结点key上移,删除结束。否则执行第6步
6,当前结点和兄弟结点及父结点下移key合并成一个新的结点。将当前结点指向父结点,重复第4步