 基于比较的排序算法的最坏情况下的最优下界为什么是O(nlogn)
基于比较的排序算法的最坏情况下的最优下界为什么是O(nlogn)
# 先解释一下问题
常见的排序算法一般分为以下两种:
1,比较排序:指将待排序的元素两两比较,满足一定条件时交换位置,直到排序完成为止,比如选择排序、快速排序等
2,非比较排序:非比较类排序则不涉及元素之间的比较,而是将元素按照一定类别分类,最后将不同的类别按大小顺序接在一起以完成排序,一般时间复杂度为O(n),比如计数排序、桶排序等
而下界就是对于一个长度为n的序列所需要的最少比较次数,又分最坏下界和最优下界
最优下界,考虑一种特殊情况,该情况下算法的比较成功导致代码块执行次数最少,这种情况就是最优下界
最坏下界,该情况下算法的比较成功次数最多,这个算法的任何其他情况不可能比这种情况执行的更慢了
那么问题来了,基于比较的排序算法的最坏情况下的最优下界为什么是O(nlogn),为什么不能比O(nlogn)更小
# 决策二叉树
了解决策树是解决这个问题的关键
决策树的每一个结点的两个子节点都代表一次判断引出的两个结果,而这个结点就代表当前情况,叶子节点代表这个问题的所有可能,路径是判定条件
来用顺序搜索和二分查找来理解一下决策树
二分思想的决策树十分平衡,因此每次猜测无论是对还是错都能将够将数字的范围缩小一半。最优下界即二叉树的深度,具有L片树叶的二叉树的深度至少是logL,所以logn是n个数字的下界
而顺序搜索那棵二叉树,虽然很有可能在第一次分支处就找到答案,但是却有很大的概率会失败(需要接着往下猜),这个时候回过头来看刚刚的决策——仅仅将范围缩小了一点点,所以n是此算法的n个数字的下界
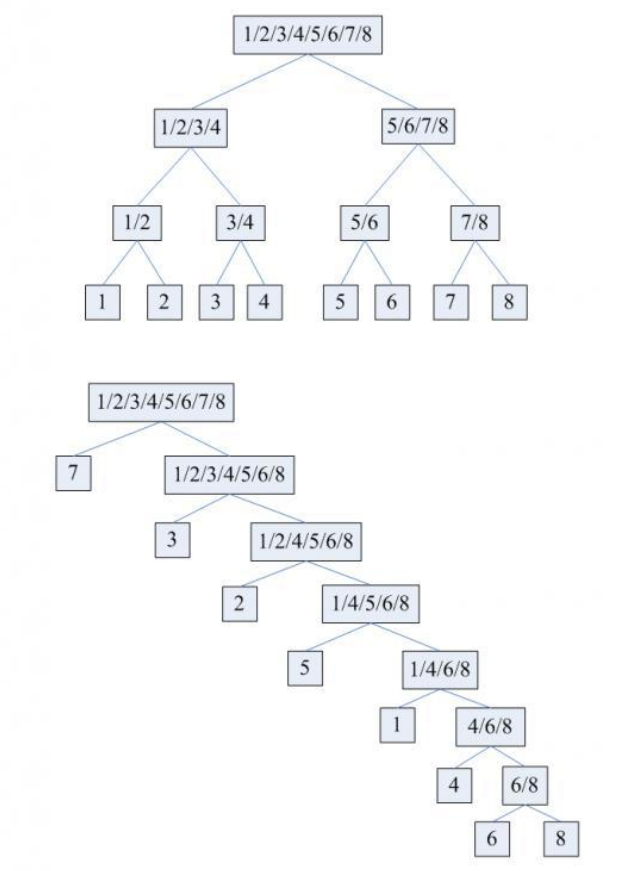
# 比较排序的决策树模型
a1,a2,a3……an放在一个数组中总共有n!种情况,其中它们按顺序排序所占的概率是1/n!,以此所有排序算法的决策树都有n!个叶结点
如果想要这颗树尽可能低,那么它应该是一个满二叉树,根据满二叉树定理,因此结点总个数就是2*N!-1。又同时它是一颗很平衡的二叉树,即每个结点的左右子树的高度之差不大于1,所以把最底层所有结点向右靠齐,可得到一个完全二叉树。完全二叉树的高度:
d = (int)log(2 * N! - 1) + 1 = (int)log(2 * (N! - 1/2)) + 1 > log(2 * (N! -1/2)) >= log(N!)
这个公式简单来说就是有n个叶节点的满二叉树高度为logn,因此n!个叶节点的满二叉树高度为log(n!)
接下来就是证明log(n!)=Θ(nlogn)
1,log(n!)=O(nlogn) 显然n!<n^n,两边取对数就得到log(n!)<nlog(n)
2,log(n!)=Ω(nlogn) n!=n(n-1)(n-2)(n-3)…1,把前n/2个因子(都大于n/2)全部缩小到n/2,后n/2个因子全部舍去,得 n!>(n/2)^(n/2)。两边取对数,log(n!)>(n/2)log(n/2),后者即Ω(nlogn)
# 一个例子
假设有一组三个元素的序列,我们用A,B,C来分别表示这三个元素,我们基于比较来对它排序。我们看到根节点一共有6种情况,我们执行排序算法,是需要找到我们想要的唯一情况,则排序算法就变成了下图所示的选择算法,可以有下列决策树
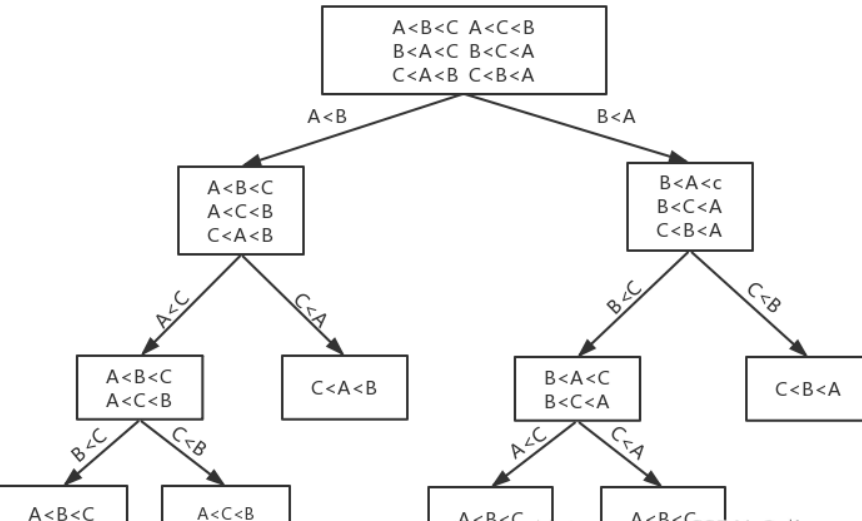 这是一个比较排序算法的决策树,虽然现在看上去非常平衡,基本和快排、堆排时间复杂度一致,但是随着元素的增加,这个树会越来越不平衡。但是无论如何,最差的情况都是叶节点,而从根节点到叶节点,需要经过 Ω(nlogn) 次选择
这是一个比较排序算法的决策树,虽然现在看上去非常平衡,基本和快排、堆排时间复杂度一致,但是随着元素的增加,这个树会越来越不平衡。但是无论如何,最差的情况都是叶节点,而从根节点到叶节点,需要经过 Ω(nlogn) 次选择