 SpringWeb 重要知识点
SpringWeb 重要知识点
主要讲述 SpringWeb 工作原理以及相关注解。MVC 本身是一种分层的设计模式思想,主要将模型和视图拆分开来便于编码,传统的 MVC 模型下包架构为 Service 层(处理业务)、Dao 层(数据库操作)、Entity 层(实体类)、Controller 层
# 主要组件
- 1,前端控制器 DispatcherServlet:MVC 的重点,从用户发送请求到返回视图给用户几乎每个过程都有它,它接受所有的用户请求,负责接收请求、分发,并给予客户端响应,同时可以做一些全局的逻辑
- 2,处理器映射器 HandlerMapping:从 url 中的信息判断应该交给哪个处理器
- 3,处理器适配器 HandlerAdapter:根据 HandlerMapping 的判断结果发送给对应的 Handler,并且统一不同类型的 Handler 调用方式,因为项目中每个 controller 出入参定义不一样,对前端控制器的影响在 HandlerAdapter 这一层屏蔽
- 4,处理器 Handler:处理请求的真正部分,就是我们写的 Controller
- 5,视图转发器 ViewResolver:根据 Handler 返回的逻辑视图,解析并渲染真正的视图,并传递给 DispatcherServlet 响应客户端
# Spring MVC 工作过程
- 1,用户的 http 请求传入前端控制器,中途会有过滤器 Filter 进行数据过滤,Filter 可以直接作用在前端控制器,代表对项目中所有的接口进行拦截
- 2,前端控制器发给处理器映射器(HandlerMapping)
- 3,处理器映射器返回执行链,HandlerExecutionChain,执行链中包含真正的处理器(Handler,通常就是 Controller 方法),以及一组拦截器 HandlerInterceptor
- 4,前端控制器发送请求给适配器,适配器负责解析参数、调用处理器、处理返回值,相当于对控制器的封装。返回一个 ModelAndView(逻辑视图名 + 模型数据)或者直接写入响应(REST 接口)
- 5,适配器发送给控制器
- 6,控制器调用服务层,返回模型(网页的内容)和视图(要跳转的网页)给适配器,适配器发给前端控制器
- 7,前端控制器发给视图解析器,视图解析器找到对应的 view,并给它发送 model
- 8,网页开始渲染,并返回各用户
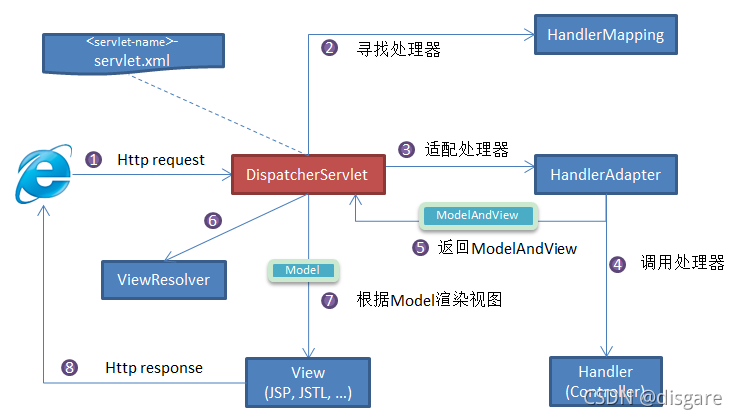 补充一下上图中的核心知识点:
补充一下上图中的核心知识点:
前端控制器设计模式中的一种架构模式,在 Web 应用中扮演着中央调度员的角色,它统一处理所有客户端请求,进行集中式管理
Servlet 是 Java EE 规范定义的服务器端组件,是运行在 Web 服务器中的 Java 程序,用于处理 HTTP 请求和响应
HandlerMapping(处理器映射器)的核心作用是建立请求与处理器之间的映射关系,请求路由问题(将不同的URL请求映射到对应的处理器),它支持多种映射策略(注解、XML 配置等),最重要的是,这么设计符合单一职责原则
HandlerAdapter(处理器适配器)解决了处理器多样化带来的问题,它让我们可以统一调用接口,举个例子,不同类型的 Controller 有不同接口
// 旧式Controller接口
public interface Controller {
ModelAndView handleRequest(HttpServletRequest req, HttpServletResponse res);
}
// 注解方式
@Controller
public class MyController {
@RequestMapping("/test")
public String handle() { return "view"; }
}
2
3
4
5
6
7
8
9
10
11
HandlerAdapter 让我们可以统一的调用这些接口,就算你想在 MyController 中拿到 HttpServletRequest 也是可以的,如果你要屏蔽 HttpServletRequest 也是可以的,它封装了一层,让我们的调用更加简洁
# 转发和重定向
在控制器中返回的 String 前加入 redirect 或者 forword 来决定是转发还是重定向
转发是服务器行为,客户端无法了解详细过程,转发只能将目的地址转到当前项目中其他文件,并且用户的 url 不会改变
重定向是客户端行为,响应行中的状态码以3开头,客户端给用户发送一个新地址,用户去访问新地址
其中301状态码是永久重定向(Moved Permanently),表示所请求的资源已经永久地转移到新的位置,这包含域名的改变或者是资源路径的改变。301是为了解决域名更换的问题,域名更换属于网站改版的一种情况,域名 A 用301跳转到域名 B,搜索引擎爬虫抓取后,会认为域名 A 永久性改变域名 B,或者说域名 A 已经不存在,搜索引擎会逐步把域名 B 当做唯一有效抓取目标。域名更换,必须保证所有页面301跳转至新域名的相应页面。在域名更换后的一定时期内,旧域名在搜索引擎中仍然会被查到。但随着权重转移,旧域名最终会被清除出搜索引擎数据库
302状态码是临时重定向(Move Temporarily),表示所请求的资源临时地转移到新的位置,一般是24到48小时以内的转移会用到302。应用场景为网页跳转、身份验证、表单提交
# 常用注解
# 前端向后端传参
在 ajax 请求之前可以加一个相应的 method 为 options 的请求
HTTP 的 OPTIONS 方法用于获取目的资源所支持的通信选项。客户端可以对特定的 URL 使用 OPTIONS 方法
简言之,options 请求是用于请求服务器对于某些接口等资源的支持情况的,包括各种请求方法、头部的支持情况,仅作查询使用
说回正题,前端向后端传参分为 get 与 post 两大类,有这几种方式:
# GET 传参
GET 传参的参数信息一般在 url 中
@PathVariable:使用 get 接受路径参数,很简单
@GetMapping("/selectOne/{id}")
public User selectOne(
@PathVariable("id") Long id) {...}
2
3
@RequestParam:该注解功能有两种,第一种是接受查询参数,该请求的 url 为 /selectOne?id=141,我比较喜欢用这个
@GetMapping("/selectOne")
public User selectOne(@RequestParam("id") Long id) {...}
2
该注解允许使用 map 与数组来接收所有的请求参数
@RestController
public class HelloController {
@GetMapping("/hello")
public String hello(@RequestParam Map<String, Object> map){
return "图书: " + map.get("name") + " 的作者为: " + map.get("author");
}
}
2
3
4
5
6
7
8
 RequestParam 还允许接受日期,只要你定义好了参数的反序列化方式
RequestParam 还允许接受日期,只要你定义好了参数的反序列化方式
@GetMapping("testDate")
public ResponseResult<?> testDate(@RequestParam("testDate")
@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss") Date testDate) {
log.info("接收的日期:" + testDate);
return ResponseResult.success(testDate);
}
2
3
4
5
6
什么也不写:什么也不写是可以接受参数的,一般用于多条件分页查询时前端传入的非常多的参数。使用 get 方法来接受这些参数,同时这些参数应当附加在路径上传入,spring 会根据 User 中的字段名称自动绑定数据
@GetMapping("/queryUserByConditionPage")
public Result<Page<User>> queryUserByConditionPage(Page<User> page, @RequestParam User user) {
return Result.success(userService.page(page, new QueryWrapper<>(user)));
}
2
3
4
注意,该 Page 的分页构造器需要自己写,用 jpa 自带的 PageRequest 不行,因为没有自带的默认构造方法,如果想要使用,想要这么写
/**
* 分页查询所有数据
*
* @param page 分页对象
* @return 所有数据
*/
@RequestMapping(value = "/query.json")
@ResponseBody
public JsonData query(int page, int size, SecondKillBatch secondKillBatch) {
return JsonData.success(secondKillBatchService.queryByPage(secondKillBatch, new PageRequest(page, size)));
}
2
3
4
5
6
7
8
9
10
11
不加任何注解时,java 解析参数的原理应该是先调用 pojo 的无参构造方法,然后通过方法里提供的 set 方法将同名称的数据一个个塞进去
# POST 传参
@RequestParam 的第二种用法是接受请求体中的参数,当请求头中的 Content-Type 类型为:multipart/form-data 或 application/x-www-form-urlencoded 时,该 @RequestParam 注解同样可以把请求体中相应的参数绑定到 Controller 方法的相应形参中
不加任何注解:如果在 post 请求中不加任何注解,也是通过 multipart/form-data 接受数据的
@RequestBody:接受前端 JSON 数据,将 JSON 中与对象属性一致的元素赋值到该对象中,该注解应该使用在 POST 请求中。对于前端而言,会将请求的数据放在请求体中
get 请求也可以使用该注解,不过因为该注解是用来读取请求体中的数据,而 get 不应该有请求体,因此不太符合规范
可以设置不提交 RequestBody 的对象,需要将注解中的 required 属性设置为 false
@PostMapping("/sign-up")
public ResponseEntity signUp(@RequestBody UserRegisterRequest userRegisterRequest) {
userService.save(userRegisterRequest);
return ResponseEntity.ok().build();
}
public @interface RequestBody {
boolean required() default true;
}
2
3
4
5
6
7
8
9
一个请求方法应该只可以有一个 @RequestBody,但是可以有多个 @RequestParam 和 @PathVariable。如果同时存在两个 @RequestBody,那应该是接口设计出了问题
# 后端的响应数据
@Controller:定义一个类为控制器
@ResponseBody:控制器返回JSON类型数据
@RestController:@Controller 加 @ResponseBody
@RequestMapping:回应的方法
@GetMapping:对应 get 请求
@PostMapping:对应 post 请求
@PutMapping:对应 put 请求
@DeleteMapping:对应 delete 请求
这里重点强调一下 post 与 put 的区别,关于使用方面,post适用于增加数据,put适用于修改数据
他两本质区别是,post 请求一般设计成接口非幂等性的,他在调用两次 post 方法时会产生两条插入数据,而 put 请求时接口幂等性的,他在调用两次 put 方法时后一条修改会覆盖前一次修改
如果两个用户调用 put 接口去新建两个不同的数据,后一个用户将前一个用户的新建记录给覆盖了这显然是不合理的;如果一个用户调用 post 接口去修改自己信息却发现创建了一个新用户也是不合理的
# 序列化数据转换
前后端分离开发时,数据传输事实上是将后端的 pojo 或者一些其他类型的属性序列化为 json,并且传给前端。前端传给后端的数据也是 json,一般情况下,框架以及给我们封装好了转换的规则
框架会将 pojo 对象转换为 json 对象,数组与数组转换为 json 数组,int 类型转换为 int,等等等等,但是还是会遇到一些特殊情况,比如时间类,这时候就需要使用一些关于 json 转换的注解
下面来说一些常见情况:
关于时间类,比如 LocalDate、LocalDateTime 等,可以使用 @DateTimeFormat 和 @JsonFormat 注解
@DateTimeFormat:用于将指定格式的字符串转换为时间类,注解的 pattern 属性值指定的日期时间格式指定的就是要求前端传入的字符串格式
import org.springframework.format.annotation.DateTimeFormat;
......
@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm")
private LocalDateTime startTime;
// 要求传入类似 2020-11-11 11:11 的格式
2
3
4
5
@JsonFormat:用于属性或者方法,把属性的格式序列化时转换成指定的字符串格式
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
private Date endTime;
2
该注解还有很多作用,比如可以让数据只能被序列化,或者只能被反序列化,通过设置 JsonProperty 的 access 属性来确定当前属性是不是需要自动序列化/反序列化。使用 WRITE_ONLY 表示只能被写入,但是该属性不能被序列化
@JsonProperty(access = JsonProperty.Access.WRITE_ONLY)
private String mobile;
2
# 多条件分页查询
SpringMVC 为我们提供了分页功能,使用 Pageable 来使用该功能
Spring data 提供了 @PageableDefault 帮助我们个性化的设置 pageable 的默认配置。例如 @PageableDefault(value = 15, sort = { "id" }, direction = Sort.Direction.DESC) 表示默认情况下我们按照 id 倒序排列,每一页的大小为 15
@ResponseBody
@RequestMapping(value = "list", method=RequestMethod.GET)
public Page<blog> listByPageable(@PageableDefault(value = 15, sort = { "id" }, direction = Sort.Direction.DESC)
Pageable pageable) {
return blogRepository.findAll(pageable);
}
2
3
4
5
6
前端访问地址为 www.xxx.com?pagesize=10&pageno=1 即可
# 自定义分页查询
如果不使用该类,也可以使用其他的框架提供的 pager,千万不要让前端传入原始的 limit 与 offset 了。或者直接写个工具类:
@Getter
@Setter
public class Pager {
private int pageno = 1;
private int pagesize = 10;
private Integer customOffset;
public int getLimit() {
if (pagesize > 5000) {
pagesize = 5000;
}
return pagesize;
}
public Pager() {
}
public Pager(int pageno, int pagesize) {
this.pageno = pageno;
this.pagesize = pagesize;
}
public int getOffset() {
if (customOffset == null) {
return pagesize * (pageno - 1);
} else {
return customOffset;
}
}
public String toSql() {
return " limit " + getLimit() + " offset " + getOffset();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
在查询传入参数中,继承这个类即可,返回值用自定义的 PageResult 包起来
public class PageResult<T> implements Serializable {
private int total;
private List<T> list;
public PageResult() {
}
public PageResult(int total, List<T> list) {
this.total = total;
this.list = list;
}
public static <T> PageResult of(int total, List<T> list) {
return new PageResult(total, list);
}
public int getTotal() {
return this.total;
}
public List<T> getList() {
return this.list;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
说实话,JPA 提供的 PageResult 很不好用,返回的值一堆参数前端都用不到,很离谱。推荐自己写一个统一返回
# spring 中的请求拦截流程
一个请求被 servlet 接受后,在 spring 组件中会经历哪些拦截呢,我们又会在这些拦截中做什么呢。下面是一些常见的组件,按请求被接受后的时间顺序来划分:
- 进入 Filter:Filter 是 Java Servlet 规范的一部分。Filter 是更底层的机制,会拦截所有的请求,过滤器必须运行在 Servlet 容器中,适用于全局性的处理,只需要将 Filter 的 bean 放到 IOC 容器中就会生效。注意这里的 Filter 是作用于整个 Servlet 容器的,而非单个 servlet
- DispatcherServlet 分发
- 拦截器:Interceptor-preHandle。我们可以在一个 registry 中添加多个拦截器,还可以使用 Order 来定义顺序,每个拦截器只会对目标 url 进行拦截,因此他更适用于特定框架内的业务逻辑增强。拦截器用责任链模式实现
- AOP:我们的业务 AOP
- 找到接口,执行业务流程
- AOP
- 后置拦截器
- 进入全局异常捕获器:ControllerAdvice,如果在前面的流程中抛出异常的话,会进入这里面做处理,如果在这里面再抛出异常的话,会按照 spring 默认的异常处理器处理(返回500)
- Filter 后置处理,最终离开 Filter
# 拦截器实现
Spring 拦截链(Interceptor Chain)是 Spring 框架中实现横切关注点(如事务管理、安全控制、日志记录等)的核心机制,主要通过 AOP(面向切面编程) 和责任链模式来实现,拦截器作用在过滤器之后,对接口进行拦截
链式调用通过 MethodInvocation 依次执行拦截器,前置拦截器代码如下,后置拦截器也差不多是这样
boolean applyPreHandle(HttpServletRequest request, HttpServletResponse response) throws Exception {
HandlerInterceptor[] interceptors = getInterceptors();
if (!ObjectUtils.isEmpty(interceptors)) {
for (int i = 0; i < interceptors.length; i++) {
HandlerInterceptor interceptor = interceptors[i];
if (!interceptor.preHandle(request, response, this.handler)) {
triggerAfterCompletion(request, response, null);
return false;
}
this.interceptorIndex = i;
}
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14