 集群间数据同步的目的
集群间数据同步的目的
# 集群间数据同步的目的
主要服务于高可用/灾备、低延迟访问、负载均衡、扩展这三大核心目标:
1,高可用性与灾难恢复,这是最核心的驱动力。当一个集群因硬件故障、网络中断、软件错误、自然灾害或人为失误而不可用时,位于其他位置的备份集群可以接管服务,确保业务连续性 2,读写分离与水平扩展,当单个集群的读写负载达到瓶颈时,将只读流量分散到多个包含相同数据副本的集群上,可以分担压力,提高系统整体的吞吐量和处理能力 3,低延迟访问:如 CDN、异地机房这些,虽然看上去和第二点类似,但是此处更倾向与将数据放在离用户更进的地方,以及冷热分离
# 集群间数据同步方式
数据同步的本质是将变更从一个集群传播到其他集群,不同技术根据其设计目标(CP 或者 AP、吞吐量、延迟敏感性)采用不同策略
1,redis:默认异步同步,主节点推送写命令(或 RDB 快照 + 增量命令,只有在第一次连接时才会执行)到从节点,增量同步时默认采用异步复制,机器维护和从机间的心跳检测,心跳检测是带有复制偏移量的
主机可配置至少有几个从机链接,以及和从机间 gap 最大允许多少。如果没有符合条件的从机,那么主机会拒绝写入请求。底层原理一般是异步同步写入指令以及心跳检测构建成的。如此设计的哲学是 redis 面向高可用的场景,需要处理容灾以及高 qps 等问题,因此异步写入数据,但是拒绝写入策略又在高可用性下维护了集群的一致性
在去中心化集群部署时从节点只用于崩溃恢复,哨兵模式或者主从部署时可以用于读写分离
2,MySQL:底层基于 Binlog,主库记录数据变更,在事务提交时主库主动告知从库,从库通过 I/O 线程拉取日志,SQL 线程重放变更
db 可以配置异步同步、半同步和全同步,他们主要是返回用户请求的时机不一样,全同步是所有从机返回应答后才回复,半同步是某个从机返回应答后才回复,全同步则是所有从机回复后才能回复用户
3,kafka:kafka 主分区接受到消息后,从副本会不断主动拉取主副本的消息,并且给主分区同步自己的偏移量以维护高水位 HW 这个值
kafka 如此设计主要是为了保证高吞吐量,主动同步给从副本可能会影响主副本性能。用户可以配置 ack 机制设置不同的返回时机,比如默认的是确认主分区收到消息后才返回,可以设置异步返回,也可以设置 kafka 同步完所有的副本后才返回
4,es:es 同步方式和 mysql 类似,可能他们都是存数据的地方吧,主分片执行完事务后会主动同步从分片
es 也可以配置写入策略,默认是大多数分片写入后才返回用户,也可以配置异步返回或者全同步
5,zk:集群间使用 zab 协议的消息同步来保证数据的一致性,是为数不多的 cp 架构,zab 的使用也类似 poxas 算法,同步的目的是为了崩溃恢复和抗住更多读请求压力
具体做法为主机向从机发事务和准备提交命令,一半以上从机返回 ack 后主机发送执行命令,然后返回用户
综上,数据同步按其目的会大致分为:
- 1,阻塞半同步(MySQL、es)
- 2,阻塞全同步(zk 使用 zab 保证全同步、MySql 的组同步、redis 高版本可设置全同步,一般都是基于 Poaxs 算法实现)
- 3,异步同步+心跳检测(redis)
- 4,等待从机同步(kafka)
# 出现主机挂机如何崩溃恢复
如果集群以崩溃恢复为目的,出现了主机挂机,他们后续会如何操作呢?
1,redis:redis 一般有三种集群部署机制,每种崩溃恢复都不太一样
- 主从:raft
- 哨兵:大部分集群检测到主机下线后,使用 raft 算法在哨兵集群中选出一个主机,过程就是按照一定的优先级(提案 ID 优先、机器编号优先、纪元优先等策略)加半数选举机制选择,主机来处理故障转移等操作。故障转移会优先选择偏移量较大的机器作为主机
- cluster:多主多从,某个主机下的从机检测到主机宕机后(使用 gossip 协议检测),会使用 raft 算法直接选出一个主机
2,MySQL:MySQL 中不同的部署方式会有不同的崩溃恢复机制
如果是传统主从复制(异步/半同步),会检测是否有 VIP 或 Proxy,如果有则 VIP 漂移到从库,如果没有则需要手动执行 CHANGE MASTER 切换
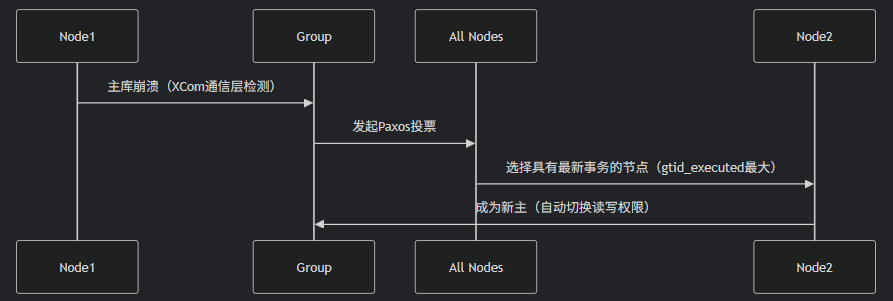
如果是组复制,则参考了 paxos 协议
 3,kafka:崩溃恢复有两种机制
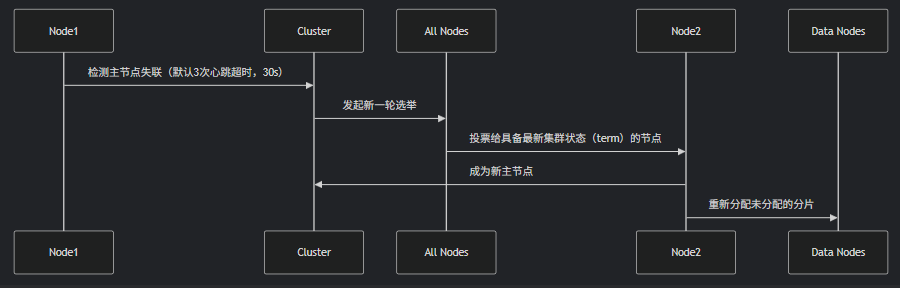
3,kafka:崩溃恢复有两种机制老:znode 机制。需要依靠 zk,从机在检测到主副本挂了后,会向 zk 集群申请自己为 controller,申请成功,则会进行检测主副本是否存活、选定新副本为主副本等操作。故障转移会优先选择 ISR 中的机器,如果没有会选择偏移量最大的机器或者等待之前的主机恢复
新:kraft 机制,不用依靠 zk 了,像 redis 一样,内部使用 raft 选出一个机器为 controller,执行后续操作
4,es:基于 Raft 变种做崩溃恢复,和 MySQL 类似
5,zk:使用 zab 协议的崩溃恢复机制,zab 抄袭了 paxos 的思想,也是每个机器会尝试发送提案,提案 ID 较大(如果提案 ID 一样则比较机器 ID)的选择为新主机,后续进行数据同步的操作
综上,大多数集群的容灾机制,都使用了 paxos 算法或者其变种算法(raft、zab)
# 持久化机制
各个数据库和中间件都有持久化机制,持久化可以保证机器挂掉后,重启可以恢复到之前正确的状态。我们来比较一下他们有什么不一样的地方
1,redis:redis 一般用于缓存,其持久化机制为 rdb 和 aof
- rdb 为内存二进制快照,适合全量备份,落库时机为每 x 秒内有 y 条数据变更则落库,可用于在集群间同步数据和崩溃恢复
- aof 为逻辑语句,落库时机为执行完一条语句后就会落库,可同步增量数据。由于 aof 后续会记录很多没用的数据,因此 redis 会有 aof 重写优化
2,MySQL:MySQL 用于记录数据,主要日志为 binlog、redolog、undolog 和 db 里本身的数据,除了同步数据外他们还需要支持回滚和重做等操作
- undolog 和原本数据落库时机为脏页回刷时,日志内容为整条数据
- binlog 和 redolog 落库时机默认为事务提交时(双1设置),binlog 日志内容默认为行记录,redolog 则是物理日志,默认内容为 xxx 事务在将 xxx 改成了 xxx
3,kafka:消息按分区存储为顺序追加的日志文件,每个 Segment 包含一个数据文件和索引文件,写入时先追加到 Page Cache,由操作系统异步刷盘
4,es:数据写入先到内存缓冲区,定期刷新到文件系统缓存,再通过 fsync 刷盘,事务日志记录未提交的操作,默认每次请求同步写入
5,zk:所有写操作顺序追加到磁盘文件,每次写入后同步刷盘,同时会定期将内存数据树序列化到磁盘,用于快速恢复

综上,持久化机制就是记录物理或者逻辑日志然后同步或者异步或者定时刷盘