 数据库分库分表
数据库分库分表
# Mysql 大表优化
如果存储的数据过多,查询效率会大大降低,如何去解决这个问题?
1,限定数据的范围:禁止不带任何限制数据范围条件的查询语句,这样就不用查询整个数据库
2,范式优化(垂直拆表):优化为 BC 范式,删除重复数据,或者单纯的拆字段
3,水平拆表:保持数据表结构不变,通过某种策略将存储的数据分片。这样每一片数据分散到不同的表或者库中
4,读写分离:主读副写,配置一下来实现 mysql 的主从复制
今天介绍的重点就是垂直拆表(拆字段)和水平拆表(拆数据)
# 分表
垂直分表:表中的字段较多,一般将不常用的、数据较大、长度较长的拆分到扩展表。一般情况加表的字段可能有几百列,此时是按照字段进行数竖直切。注意垂直分是列多的情况
垂直分表的拆分原则是将热点数据(可能会冗余经常一起查询的数据)放在一起作为主表,非热点数据放在一起作为扩展表。这样更多的热点数据就能被缓存下来,进而减少了随机读 IO。拆了之后,要想获得全部数据就需要关联两个表来取数据。但记住,千万别用 join,因为 join 不仅会增加 CPU 负担并且会讲两个表耦合在一起
水平分表:单表的数据量太大。按照某种规则(RANGE、HASH 取模等),切分到多张表里面去。 但是这些表还是在同一个库中,所以库级别的数据库操作还是有 IO 瓶颈。这种情况是不建议使用的,因为数据量是逐渐增加的,当数据量增加到一定的程度还需要再进行切分。比较麻烦
阿里巴巴的《Java开发手册》提出:
单表行数超过500万行或者单表容量超过2GB,才推荐进行分库分表。
当然每个业务方向有不同的分表机制,QPS、数据量、业务场景等不同,需要根据实际情况来选择分表机制。同时由于每个公司数据库硬件配置不同,分表的阈值也不同。请在分库分表前预估数据量级以及 QPS,根据这两个指标咨询 DBA 同学,并且观察历史业务得出一个合理的分表阈值以及分表的数量
同时注意,分库分表不要自己手写代码,这样容易和业务代码耦合,维护起来很困难。我在线上就见过以 product_id 的某位分成10个表的业务代码,我们可以借助一些框架处理这个问题,比如 MyCAT、Cobar 之类的
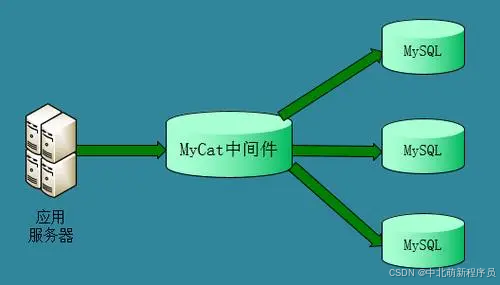
# MyCat
Mycat 是数据库中间件,所谓中间件数据库中间件是连接 Java 应用程序和数据库中间的软件
- 一个彻底开源的,面向企业应用开发的大数据库集群
- 支持事务、ACID、可以替代 MySQL 的加强版数据库
- 一个可以视为 MySQL 集群的企业级数据库,用来替代昂贵的 Oracle 集群
- 一个融合内存缓存技术、NoSQL 技术、HDFS 大数据的新型 SQL Server
- 结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品 一个新颖的数据库中间件产品
Mycat 作用为:能满足数据库数据大量存储;提高了查询性能
# sharing-sphere
Apache ShardingSphere 是一款分布式的数据库生态系统, 可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强
sharing-sphere 可以用来实现进行多库分表,只需要一些简单的配置即可
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
</dependency>
2
3
4
5
6
7
8
9
10
11
12
13
相关配置:
spring:
shardingsphere:
props:
sql:
## 打印sql
show: true
datasource:
// 使用两个库 ds0 和 ds1
names: ds0
ds0:
jdbc-url: jdbc:mysql://127.0.0.1:3306/your_database?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: 123456
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
ds1:
.......
sharding:
## 数据分片规则配置
tables:
## 逻辑表名称
document_trans:
## 由数据源名 + 表名组成(参考 Inline 语法规则)
## actual-data-nodes: ds0.document_trans_? (?代表任意个表),如果是 ds0.document_trans_$->{0, 31} 就表示0到31个表
actual-data-nodes: ds0.document_trans_?
## 分表策略
table-strategy:
## 用于单分片键的标准分片场景
standard:
## 自定义分片算法实现类
precise-algorithm-class-name: com.xxx.algorithm.table.MyTableStandardPreciseAlgorithm
## 除了分片算法实现类,我们还可以使用 sharding-algorithm-name 来指定一些比较简单的分片算法
sharding-algorithm-name: my-table-algorithm
## 分片列名称
sharding-column: enterprise_id
## 分片算法配置
sharding-algorithms:
## 上面定义的分表算法
my-table-algorithm:
## 该分表算法的类型
type: INLINE
props:
## 具体的分表算法,我们采用 enterprise_id 除以32的余数来算
algorithm-expression: document_trans_$->{enterprise_id % 32}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
配置完毕后自动进行分表,但是有一个缺点,就是后续查数据可能比较麻烦了
官网:sharing-sphere (opens new window)
shardingsphere 高版本(5.1.x以上)导入的时候可能会遇到一个问题
Caused by: org.springframework.beans.factory.NoSuchBeanDefinitionException: No qualifying bean of type 'org.apache.shardingsphere.infra.config.mode.ModeConfiguration' available: expected at least 1 bean which qualifies as autowire candidate. Dependency annotations: {}
ModeConfiguration 找不到,这时候需要在 application.yml 中配置,或者在代码中创建 ModeConfiguration,推荐用以下配置
shardingsphere:
props:
sql-show: true
mode:
type: Standalone
repository:
type: File
props:
path: classpath:config/shardingsphere
2
3
4
5
6
7
8
9
# 分库
业务分库:一个数据库的表太多。此时就会按照一定业务逻辑进行垂直切分,比如用户相关的表放在一个数据库里,订单相关的表放在一个数据库里。注意此时不同的数据库应该存放在不同的服务器上,此时磁盘空间、内存、TPS 等等都会得到解决。这个一般在业务线上都有涉及
使用业务分库基本上就可以服务化了。例如,随着业务的发展一些公用的配置表、字典表等越来越多,这时可以将这些表拆到单独的库中,甚至可以服务化
数据分库:水平分库理论上切分起来是比较麻烦的,它是指将单张表的数据根据某种依据(hash、range 等)切分到多个服务器上去,每个服务器具有相应的库与表,只是表中数据集合不同。 水平分库分表能够有效的缓解单机和单库的性能瓶颈和压力,突破 IO、连接数、硬件资源等的瓶颈
分库后可能遇到事务问题、分布式 ID 问题等,在我的其他博客中都有详细介绍
# 分库分表常见问题
# 非 partition key 的查询问题
partition key 表示数据分库的依据,比如我们按照主键的奇偶性,去将数据分到两个库中。此时主键就是 partition key。如果用户使用了其他字段做查询,就比较麻烦了
此时我们可以先将这其他字段转换为主键,然后再查询,如果希望每次查询时不这么麻烦,可以将数据整合放入中间件中,比如将数据放进 es 中,从 es 中查出主键,然后去数据库中查询完整的数据
某些特殊情况下,还可以用基因法,比如非分表键可以解析出分表键出来,比如常见的,订单号生成时,可以包含客户号进去,通过订单号查询,就可以解析出客户号
其实该问题还有问题变种,就是跨节点 Join 关联问题,需要在查询时,将多个节点的数据合并起来。解法可以是提前将数据写进 es,或者在建表的时候,就提前把需要关联的字段放入主表中,避免关联操作;或者分开多次查询,调用不同模块服务,获取到数据后,代码层进行字段计算拼装
# 扩容问题
数据太多了,我们先再增加几个库存放这张表的数据。此时我们可以借鉴 java 中 hashmap 扩容的做法。扩容是成倍的,就像下图一样,大致思路先新增两个机器,然后双写数据,然后迁移数据,完成后删除旧机器中的数据
