 flink 提交流程
flink 提交流程
# 基础架构
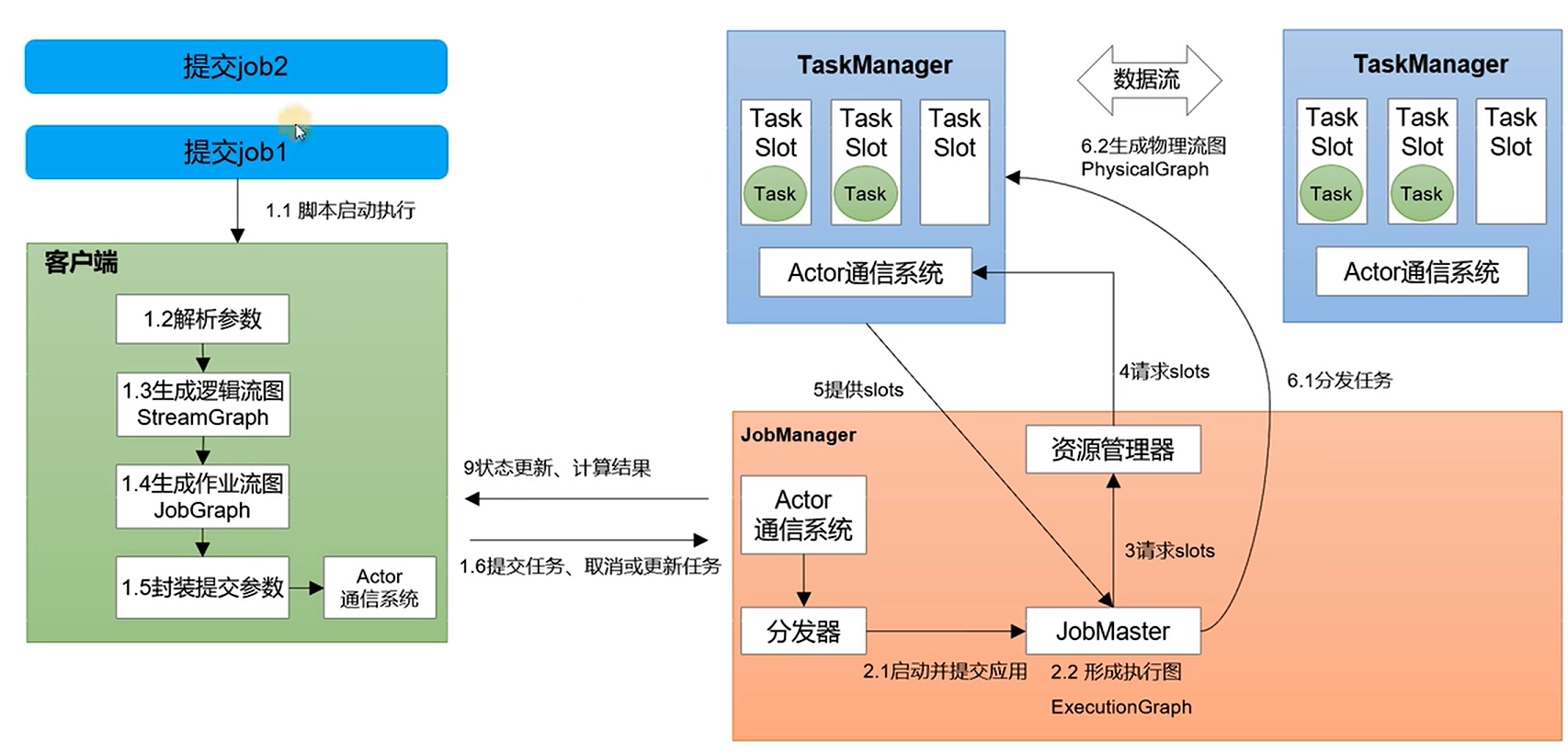 上图是普通的 standalone 架构,就是独立模式,会话模式部署,客户端在接受 job 时,会生成逻辑流图,这里只是按照业务生成对应的执行图,到了 JobManager 中,会生成作业流图,这里做了算子合并等操作,然后请求 TaskManager 看看有没有空余的槽位,如果有,在最终传给 TaskManager 后才会根据槽数量生成最终的执行流图
上图是普通的 standalone 架构,就是独立模式,会话模式部署,客户端在接受 job 时,会生成逻辑流图,这里只是按照业务生成对应的执行图,到了 JobManager 中,会生成作业流图,这里做了算子合并等操作,然后请求 TaskManager 看看有没有空余的槽位,如果有,在最终传给 TaskManager 后才会根据槽数量生成最终的执行流图
如果没有槽位了,并且如果是配置了弹性扩缩容(如 Kubernetes 的 Horizontal Pod Autoscaler 或者 yarn),Flink 的 ResourceManager 会尝试 自动申请新的 TaskManager,如果是 Standalone 模式,就会直接报错
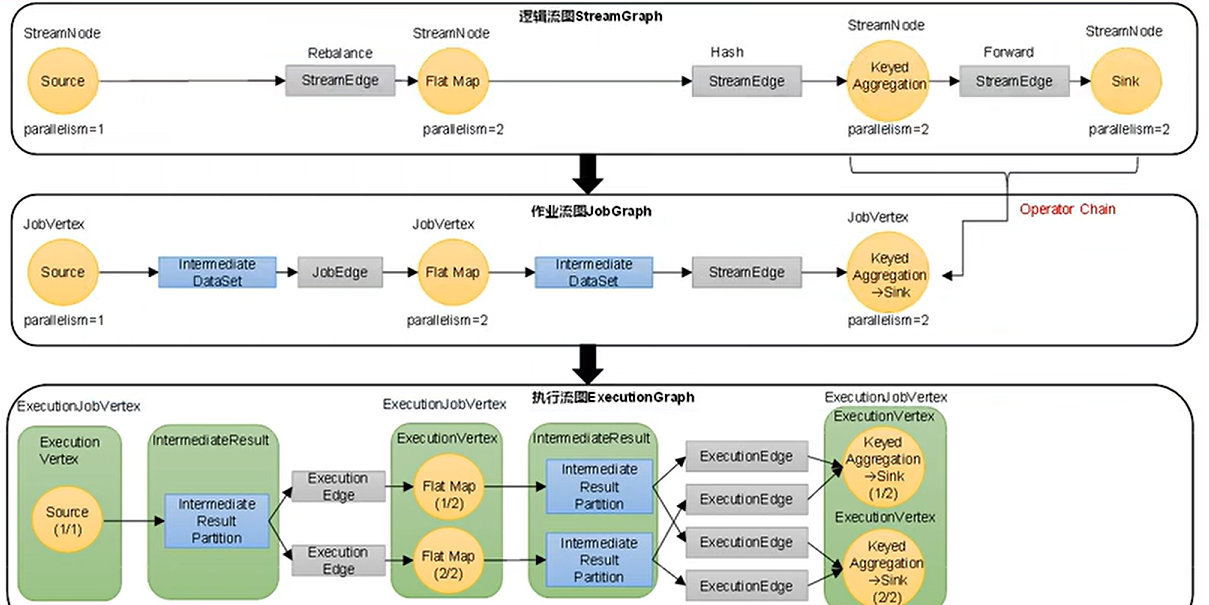
这种模式非常简单,但是在出现错误或者任务量过多的时候,不好做容错或者扩容,下图是流图的生成实例
 下面是引入了 yarn 的架构
下面是引入了 yarn 的架构
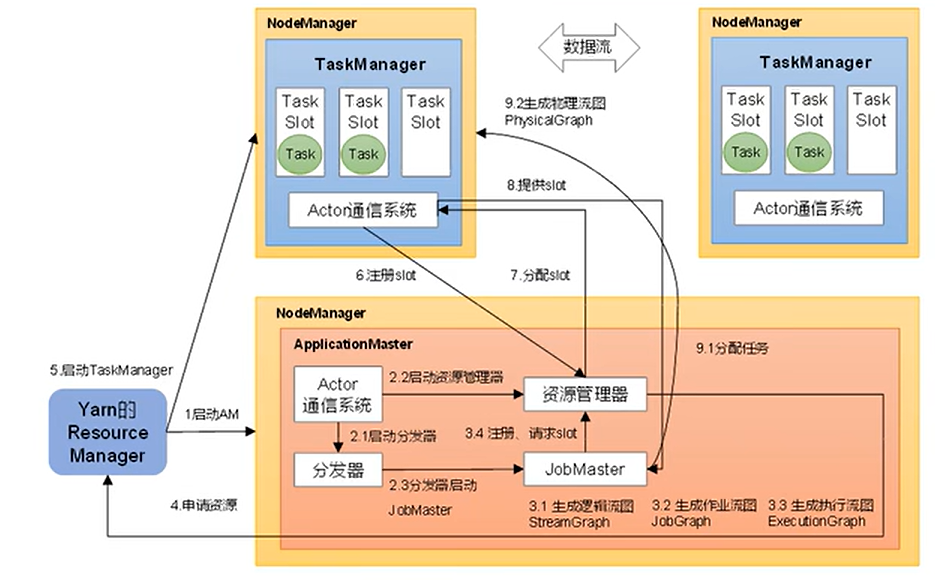 工作中比较推荐的还是引入了 yarn 模式的 flink
工作中比较推荐的还是引入了 yarn 模式的 flink
# 并行度
当要处理的数据量非常大时,我们可以把一个算子操作,复制多份到多个节点,数据来了之后就可以到其中任意一个执行
这样一来,一个算子任务就被拆分成了多个并行的子任务(subtasks),再将它们分发到不同节点,就真正实现了并行计算。在 Flink 执行过程中,每一个算子可以包含一个或多个子任务,这些子任务在不同的线程、不同的物理机或不同的容器中完全独立地执行
一个算子的子任务个数就是它的并行度,一般情况下一个流程序的并行度是流所包含的算子的最大并行度。并行度 = 任务拆分为多个并行实例,每个实例处理数据的一个子集
# 算子链
flink 分两种模式,一种是直连,另一种是打乱的重分区模式,具体是哪一种形式,取决于算子的种类
- 一对一(One-to-one,forwarding):这种模式下,数据流维护着分区以及元素的顺序。比如 source、map 算子等,source 算子读取数据之后,可以直接发送给 map 算子做处理,它们之间不需要重新分区,也不需要调整数据的顺序。这就意味着 map 算子的子任务,看到的元素个数和顺序跟 source 算子的子任务产生的完全一样,保证着一对一的关系。map、filter、flatMap 等算子都是这种 one-to-one 的对应关系。这种关系类似于 Spark中的窄依赖。直连算子在执行时会合并在一起,避免了重分区之间的数据传输消耗
- 重分区(Redistributing):在这种模式下,数据流的分区会发生改变。比如 keyBy 算子和 Sink 算子之间是这样的关系。每一个算子的子任务,会根据数据传输的策略,把数据发送到不同的下游目标任务,就是一对多的方式
Flink 默认会将连续的、满足条件的算子(如相同的并行度、无数据重分区等,如 Source → Map 这种一对一的算子)合并成一个物理执行单元(Task),Task 就是一个算子链
这么做的目的是为了减少线程切换、网络序列化等开销,提升性能
# 任务槽
Flink 中每一个 TaskManager 都是一个 JVM 进程,它可以启动多个独立的线程,来并行执行多个子任务(subtask)
很显然,TaskManager 的计算资源是有限的,并行的任务越多,每个线程的资源就会越少。那一个 TaskManager 到底能并行处理多少个任务呢?为了控制并发量,我们需要在 TaskManager 上对每个任务运行所占用的资源做出明确的划分,这就是所谓的任务槽(taskslots)
每个任务槽其实表示了 TaskManager 拥有计算资源的一个固定大小的子集。这些资源就是用来独立执行一个子任务的,这里的槽会将管理的内存平均分为 x 份,这里的 x 就是槽数量,只对内存做切分不对 CPU 资源做切分,因此我们平时设置的任务槽数量一般和 CPU 数量一致
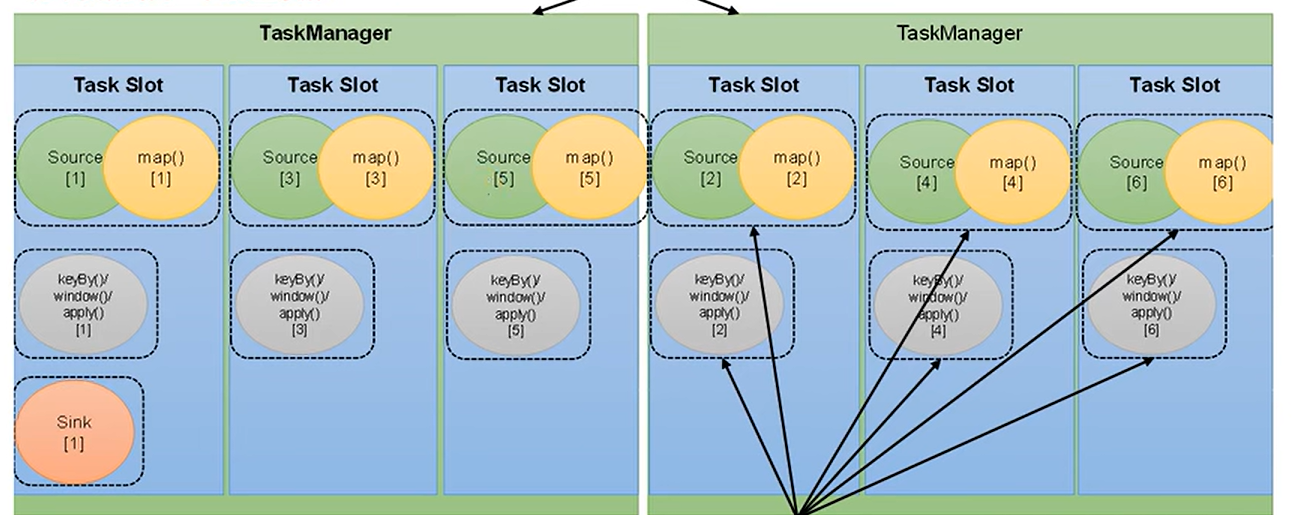 一个完整任务执行流程中是不允许存在并行度大于槽数的算子的
一个完整任务执行流程中是不允许存在并行度大于槽数的算子的
默认情况下,Flink 允许多个算子的任务实例共享同一个 Slot,但是同一算子的不同并行实例(即同一个算子的多个任务副本)必须分配到不同的 Slot,即使 Slot 共享组允许其他算子的任务共享 Slot
相信定义介绍到这里大家也看出来了,Flink 定义槽数其实为了将一个任务拆到最细,并且最大限度的利用内存和 CPU 资源