 MySQL 基本的特性
MySQL 基本的特性
# MySQL 基本的特性
1,不区分大小写,为了让语句可读性更高,所有的关键字大写,列名表名小写 2,每条命令应该以;结尾,并且一条命令可以换行
基础的sql命令如下
-- 展示所有的库名
show DATABASES;
-- 创建一个数据库
create database ...;
-- 使用student库
use student;
-- 展示库中的表
show TABLES FROM student;
-- 查看所有表,以x开始的数据库
SHOW tables;
SHOW DATABASE like 'x%';
-- 查看表定义,索引信息,字段信息,用户信息
show create table xxx
show index from xxx
show columns from xxx
show grant for 'x'@'127.0.0.1'
-- 创建一个表
CREATE TABLE tesuht(
t1 INT,
t2 INT
);
-- 获取帮助信息
help
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
此外,还可以使用set来设置mysql的变量值
# 约束
在创建表与修改表的时候添加约束,主要约束有: 非空、默认、主键、外键(限制2两个表的关系)、唯一
# 视图
像写sql语句一样写视图,通过表动态生成数据,只会存储写入的sql逻辑,不会存储表,在查询的时候,可以直接使用视图进行查询
CREATE VIEW test
AS
SELECT * FROM student WHERE Sname LIKE '李%';
SELECT * FROM test
2
3
4
5
# 权限管理
mysql的权限数据存放在一个文件中,在启动时读取mysql.user表中信息并且对链接的用户进行身份认证
## 创建用户,user后面的是用户名,@后面是允许用户登录的主机,by后面是用户密码
create user 'x'@'127.0.0.1' identified by 'password'
## 删除用户,需要同时指定用户名和ip
drop user 'x'@'127.0.0.1'
## 给在test1.*表中添加用户x的增删改查权限
grant insert, update, delete, select on test1.* to 'x'@'127.0.0.1';
2
3
4
5
6
权限又分增删改查以及ALL、 WITH GRANT OPTION等权限
# DDL 语句:编辑表
DDL 是操作表相关的语句,比较简单,在创建表之前需要先创建数据库,然后使用你需要使用的数据库
这一类语句都不可回滚,并且操作都是原子操作
## 创建表,AUTO_INCREMENT 表示自增长,一般这个属性用于主键
create table industry_table
(
id bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
merchant_id bigint not null comment '账户id',
create_time bigint not null comment '创建时间',
update_time bigint not null comment '修改日期',
status tinyint(4) NOT NULL COMMENT '状态, 0:不可用, 1:可用',
PRIMARY KEY (`id`),
KEY `idx_industry_table_create_time_key` (`create_time`),
UNIQUE KEY `uniq_short_video_merchant_id_key` (`merchant_id`)
) ENGINE = InnoDB
AUTO_INCREMENT = 1
DEFAULT CHARSET = utf8mb4
COLLATE = utf8mb4_unicode_ci COMMENT ='测试表';
## 删除表,这个命令比较危险,不可回滚
DROP table tesuht;
## 重命名表
RENAME TABLE tab_1 to tab_2;
## 删除表中的所有数据,该操作不可回滚
TRUNCATE TABLE tab;
## 修改表中字段或者索引信息,比较复杂,有以下几种形式
ALTER
## 使用 alter 添加表字段
## 在表tab_1中添加字段(column是字段的意思)city,在 char(10)后面还可以加not null等修饰符修饰
ALTER TABLE tab_1 ADD COLUMN city char(10) not null comment '城市';
## 修改
MODIFY/CHANGE
ALTER TABLE tab_1 MODIFY COLUMN city char(10) not null comment '大城市';
## 删除
DROP
## 同一张表多个字段的操作可以用逗号分隔开
ALTER TABLE tab_1 MODIFY COLUMN city char(10), DROP COLUMN city;
## 添加索引,下面是添加主键索引,如果要添加唯一索引,将 PRIMARY KEY 改为 UNIQUE,普通索引为 INDEX
ALTER TABLE table_name ADD PRIMARY KEY (city)
## 添加普通索引
alter table table_name ADD INDEX idx_table_name_volmn_key (volmn);
## 使用 create index 也可以为表添加索引,如果需要创建唯一索引,在 index 前加 UNIQUE
CREATE INDEX idx_author_id ON book (author_id);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
这类建表语句推荐使用 idea 的图形化界面,用起来非常爽,如果要修改表的话就点击 modify table
# DQL 语句
DQL 就是查询语句,查询语句都按照以下的基本格式书写
SELECT 列名、函数名
FROM 表名
WHERE 条件
GROUP BY 排序
HAVING 函数名
ORDER BY 列名
2
3
4
5
6
sql 中真实的执行顺序如下: 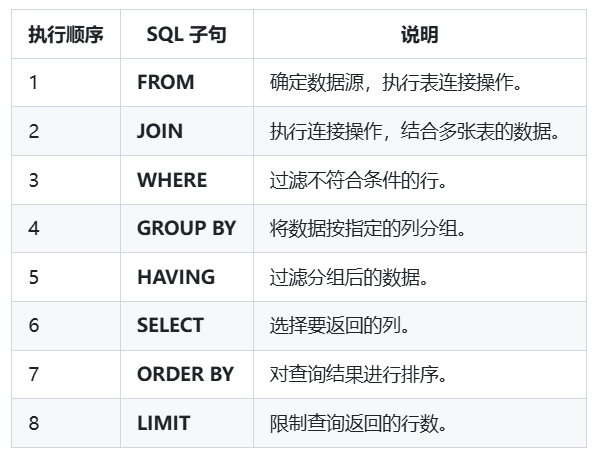
# SELECT
为列起别名:AS,AS可以省略
去重:DISTINCT
# 函数
函数:封装了一定操作的过程,和java函数相似,函数又分单行函数(给定一个数,返回另外一个数)和分组函数(给定一组数,返回一个数,一般用来做统计)
-- 单行函数
SELECT LENGTH('sdfasdf1');
SELECT CONCAT('sadf','asdf');
SELECT ROUND(-1.5);
SELECT IF(10 > 5, 10, 5);
-- 分组函数
SELECT SUM(student.Sno) FROM student;
SELECT MIN(student.sno) FROM student;
SELECT MAX(student.sno) FROM student;
SELECT COUNT(student.Sno) FROM student;
SELECT AVG(student.Sno) FROM student;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# COUNT
使用 count 函数进行计数时通常会使用下面三种方法,它们有不同的功能
- count(1):对查询的表里的数据进行计数,1表示一个固定值,其实不管是不是1,0、2、100、-100使用count得到的结果都是一样的,它就是计算满足条件的数据个数。常见的理解中这个相当于对每行提供一个常量值 1 然后计数,但是优化器会将 COUNT(1) 和 COUNT(*) 优化成相同的执行计划,两者都是找最合适的索引执行,性能和 count(*) 基本相同
- count(*):对查询的表所有数据进行计数,执行时会把星号翻译成字段的具体名字
- count(sno):对查询的表的 sno 这一列进行计数,当这一列中有 null 时不计入,在使用 group by 分组后,还可以使用 count(distinct sno) 来计数,一般来说比 count(*) 慢(因为需要排除 null 的情况)
# FROM
AS:对表起别名,如果这么做了,在其他的地方使用该表的时候也需要使用别名,不然会报错
SELECT s.sno
FROM student AS s;
2
# WHERE
条件判断:>,<,=,<>,like,IS NULL
其中like需要配合%(匹配多个字符)或者_(匹配一个字符)使用,比如
select count(*) from employee where name like '张%' and is_valid = 1
用于连接的:and、or、not
between and 用于选取一定范围的值,in 用来寻找满足要求的值,这俩个都可以使用上面的符号代替
# GROUP BY
按列分组,一般和分组函数搭配使用,可以显示每一组中的属性
SELECT COUNT(sname), ssex
FROM student
GROUP BY Ssex
2
3
# HAVING
在 having 中使用函数代表分组后筛选,因为 where 中不可以使用函数,函数只能放在 having 中
这个关键字可以衍生出很多花样,比如查询平均成绩大于等于 60 分的同学的学生编号和平均成绩
select s_id,avg(s_score)
from score
group by s_id
having avg(s_score)>=60
2
3
4
注意分完组后只能查找分组的行,其他行只能使用聚和函数表达出来,而使用 HAVING 可以对聚合函数进行筛选判断
但是也注意,having 中无法使用原来的字段,必须带函数
# ORDER BY
按列的大小排序,默认ASC从小到大排序,可以设置DESC从大到小排序
# 多表连接
如果查询多个表,就会出现笛卡尔乘积的状况,因此需要加入有效的表连接条件,比如两个表的共同内容
SELECT student.Sage, student.Sno, sc.Grade
FROM student ,sc
WHERE student.Sno = sc.Sno
2
3
# 子查询
先查询一个表,对这个表的结果做查询
SELECT * FROM student
WHERE student.Sno >
(
SELECT student.Sno
FROM student
WHERE student.Sname = 'xie'
);
2
3
4
5
6
7
# 分页查询
在实际应用非常广泛,使用limit关键字,前面一个是起始个数,后面一个是显示数量,在web的页面中,计算的公式是(page-1)*size
SELECT * FROM student
LIMIT 0, 20;
2
# 高级连接
在FROM行中使用JOIN...ON语句实现高级链接,这种方式比较清晰,推荐使用
内连接:返回两个表交集部分,on表示判断条件 语句:select * from a inner join b on a.id = b.id
左外连接:左表的数据会全部显示出来,右表的数据只会显示满足条件的部分,其他的部分使用null代替 语句:select * from a left join b on a.id = b.id
右外连接:同上
全外连接:左表和右表都不做限制,所有的记录都显示,两表不足的地方用null填充,MySQL目前不支持此种方式,可以用其他方式替代解决
# OVER ... PARTITION BY
该语句在量化中坚持被使用到,主要用于窗口函数(Window Function)中,用于将查询结果集划分成多个分区,每个分区可以独立地应用窗口函数进行计算。简单来说,PARTITION BY 的作用类似于 GROUP BY,但是它不会像 GROUP BY 那样减少结果集的行数,而是为每一行数据创建一个上下文环境,在这个环境中执行特定的操作
SELECT column1, column2, ..., window_function(column) OVER (PARTITION BY partition_column)
FROM table_name;
2
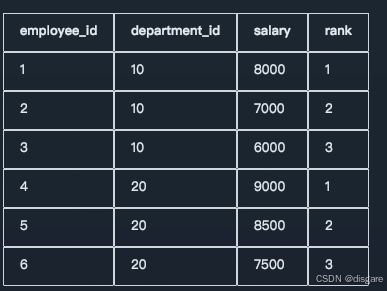
比如假设我们有一个员工表 employees,包含以下字段:
- employee_id:员工ID
- department_id:部门ID
- salary:薪资
如果我们想要计算每个部门中每位员工的薪资排名,然后让数据按照部门纬度展示出来,可以使用 RANK() 函数结合 PARTITION BY 来实现:
SELECT employee_id, department_id, salary,
-- 按照部门分类,按照薪资排序,并且用 RANK 来获取排名
RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) AS rank
FROM employees;
2
3
4
输出示例如下:
# DML 语言:数据的增删改
DML 是数据的增删改
# 增加
有两种增加方式,一种是insert into + values,另外一种是set
INSERT INTO student(sno, sname, sage)
VALUES('00000', 'adf', '20');
INSERT INTO student
SET sno = '95555', sname = 'aadsf', sage = '19'
2
3
4
5
将其他表的数据存入到该表中: INSERT 语句还可以将 SELECT 语句查询出来的数据插入到另一个表中,即可快速地从一个或多个表中向一个表中插入多个行。这样,可以方便不同表之间进行数据交换
INSERT INTO 表名1(字段列表1)
SELECT 字段列表2 FROM 表名2 WHERE 条件表达式;
2
当主键存在时,执行更新操作:ON DUPLICATE KEY UPDATE 为 Mysql特有语法,语句的作用,是当 insert 已经存在的记录时,执行 update
-- 在原sql后面增加 ON DUPLICATE KEY UPDATE
INSERT INTO user_admin_t (_id,password)
VALUES ('1','第一次插入的密码')
ON DUPLICATE KEY UPDATE
_id = 'UpId',
password = 'upPassword';
2
3
4
5
6
该语句是根据主键来进行判断,如果主键重复则执行 update。如果没有主键,此时是根据唯一索引来进行判断 ,如果唯一索引重复则执行 update
# on duplicate key
mysql 的特殊写法,旨在存在唯一主键或者唯一索引时执行补偿逻辑
-- 第一条插入;第二条更新
INSERT INTO tableA(name, type, a, b, c) values('啊喔额',11,1,2,3),('阿哈湖',6, 1,2,4) on DUPLICATE KEY UPDATE name= values(name), type = values(type)
2
使用要点:
- 表要求必须有主键或唯一索引才能起效果,否则无效
- 该语法是根据主键或唯一键来判断是新增还是更新
- VALUES 后面应为需要更新的字段,不需要更新的字段不用罗列
- 遇到已存在记录(根据唯一键或主键)时,自动更新已有的数据;如果表中有多个唯一键(可以是单列索引或复合索引),则任意一个唯一键冲突时,都会自动更新数据
- 所有操作均由 SQL 处理,不需要额外程序代码分析,能够大幅提高程序执行效率
# 修改
使用 update + set
UPDATE student
SET student.Ssex = '男', student.Sage = '20', Sdept = 'CS'
WHERE student.Sno = '00001'
2
3
多表修改语句
update a1 inner join b1 on a1.id = b1.id set a1.value1 = b1.value1
# 批量修改
有以下三种方案:
方案1,使用 WHEN THEN
UPDATE mytable
SET myfield = CASE id
WHEN 1 THEN 'value'
WHEN 2 THEN 'value'
WHEN 3 THEN 'value'
END
WHERE id IN (1,2,3)
2
3
4
5
6
7
方案2,使用 replace into。replace 底层原理是先删除后增加
replace into test_tbl (id,dr) values (1,'2'),(2,'3'),...(x,'y');
方案3,使用 insert into …on duplicate key update。这其实是新增或者更新语句,单纯用于更新也可以,这里的 duplicate key 大多数都是指主键
insert into test_tbl (id,dr)
values (1,'2'),(2,'3'),...(x,'y')
on duplicate key update dr=values(dr);
2
3
# 删除
将一行的数据删除掉,使用delete from
DELETE FROM student
WHERE sno = '00000'
2
如果要对多个表进行删除,加入对应的多表连接操作就行了,语法如下
delete employee, holiday, leave_holiday
from employee join holiday join leave_holiday
where employee.id = holiday.id and holiday.id = leave_holiday.id
and employee.is_valid = 2
2
3
4
删除操作的语法与select的join语法不太一样
# 基本函数
获取当前时间戳
#当前时间戳(秒级):2020-08-08 12:09:42
select current_timestamp();
#当前时间戳(毫秒级):2020-08-08 12:09:42.192
select current_timestamp(3);
## 秒级时间戳:1606371113 (自19700101 00:00:00以来按秒算)
UNIX_TIMESTAMP(NOW())
## 毫秒级时间戳:1606371209.293
select unix_timestamp(current_timestamp(3))
## 毫秒级时间戳:1606371209293
REPLACE(unix_timestamp(current_timestamp(3)),'.','')
2
3
4
5
6
7
8
9
10
11
12
13
14
# sql 调优
除了 explain 我们还可以用以下语句看 mysql 性能:
比如 mysql 会将慢查询记录到 events_statements_summary_by_digest 中,因此我们可以查表看数据,我们还可以通过 processlist 看出目前正在执行的查询
-- 查询最近的高耗时SQL
SELECT * FROM performance_schema.events_statements_summary_by_digest
ORDER BY SUM_TIMER_WAIT DESC LIMIT 10;
-- 查看当前运行查询
SHOW FULL PROCESSLIST;
-- 筛选长时间运行查询
SELECT * FROM information_schema.processlist
WHERE TIME > 60 ORDER BY TIME DESC;
2
3
4
5
6
7
8
9
10
我们可以看引擎状态
SHOW ENGINE INNODB STATUS\G
重点关注:
- SEMAPHORES(信号量等待)
- LATEST DETECTED DEADLOCK(死锁信息),包含死锁发生时间、涉及的事务、等待的资源、被选为牺牲品的事务等
- BUFFER POOL AND MEMORY(缓冲池状态)