 java 的常见性能问题分析以及出现场景
java 的常见性能问题分析以及出现场景
一般来说 java 出现性能问题就是代码写的不怎么样,需要使用一些命令或者工具手动定位到问题代码并进行优化
# CPU 占满
这种问题一般出现在使用了大量的计算资源,比如:
GTA5 联机版的要跑19.8亿次 if 语句、堪称游戏开发史上最大的“屎山”代码,一支烟的功夫游戏都加载不完。存在了7年,R 星从没想过要修复。这大量的 if 判断需要消耗 CPU 资源,导致 CPU 占满
那么如何定位到代码问题所在呢?
可以使用 top 命令,top 命令使我们最常用的 Linux 命令之一,它可以实时的显示当前正在执行的进程的 CPU 使用率,内存使用率等系统信息。top -Hp pid 可以查看线程的系统资源使用情况
定位到线程之后可以使用 jstack(用于生成当前时刻的线程快照。线程快照是当前 Java 虚拟机内存中每一条线程正在执行的方法堆栈的集合。生成线程快照的主要目的是定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等问题)来动态监视 jvm 的栈使用情况,jstack 输出的内容如下:
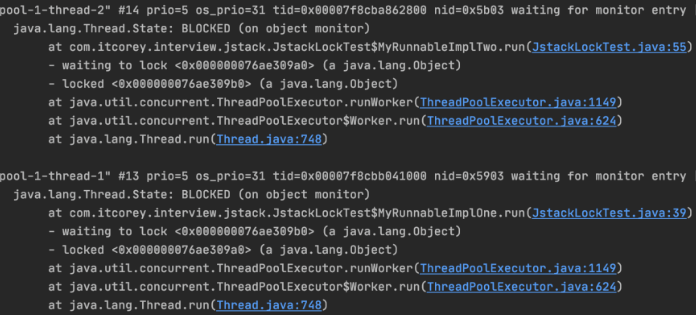 出现 CPU 占满问题,可能是线程竞争导致了频繁的上下文切换,或者代码中存在无限循环或者条件判断错误导致的死循环
出现 CPU 占满问题,可能是线程竞争导致了频繁的上下文切换,或者代码中存在无限循环或者条件判断错误导致的死循环
# 内存泄漏
程序中存在无用但是存在引用的对象
常见的情况有:忘记断开引用,使用生命周期很长的对象,ThreadLocal 使用不当
使用 JProfiler 来分析及定位内存泄漏问题
也可以使用 linux 的命令来定位问题,比如 top 和 vmstat
vmstat 是一个指定周期和采集次数的虚拟内存检测工具,可以统计内存,CPU,swap 的使用情况,它还有一个重要的常用功能,用来观察进程的上下文切换
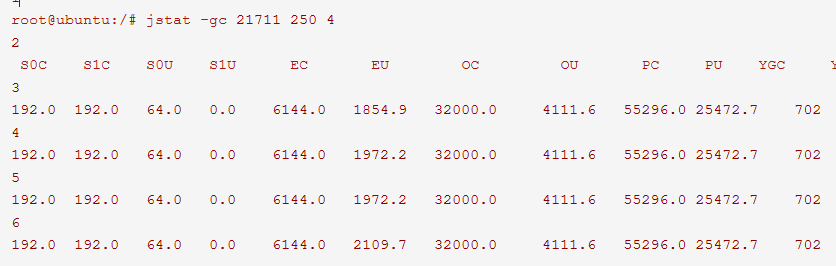
确认是 java 的内存占用过多后(业务平台应该有报警),我们可以使用 jstat(JVM统计监测工具)来看堆中每个区域占用了多大空间,下图中 EC 表示新生代大小,EU 表示使用量,OC 表示老年代大小,其他同理
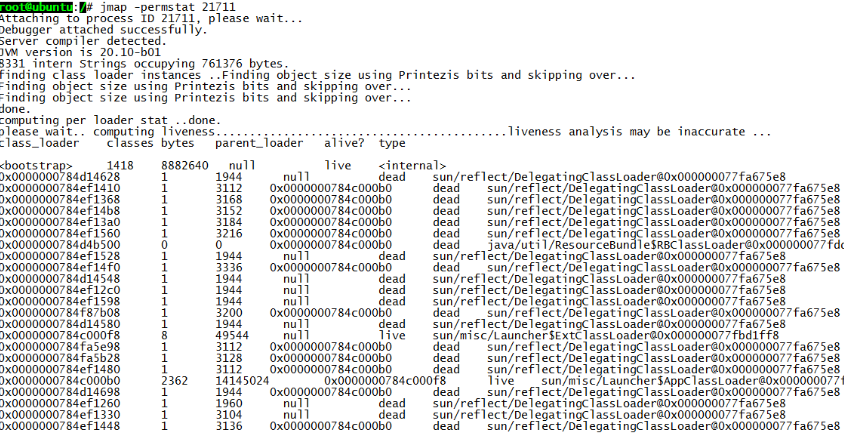
我们使用 jmap 来看堆中对象的存活情况,我们可以比较哪个对象过多或者过大导致内存泄漏
 我们还可以用 jmap 把进程内存使用情况 dump 到文件中,再用 jhat 分析查看
我们还可以用 jmap 把进程内存使用情况 dump 到文件中,再用 jhat 分析查看

请注意,堆 dump 是将 JVM 堆的完整快照写入磁盘文件的过程,因此需要 STW(Stop-The-World 事件),即暂停所有应用线程,等待 dump 完成。这会导致应用暂时不可用,因此在生产环境中应该谨慎使用
同时 JVM 也提供了很多优化措施,比如我们可以在 jmap 时只生成直方图提升速度、使用并行线程加速 dump(JDK 11+特性)、使用异步 profiler 等等
# 死锁
死锁会导致耗尽线程资源,占用内存,表现就是内存占用升高,如果是直接 new 线程,会导致 JVM 内存被耗尽,报无法创建线程的错误,这也是体现了使用线程池的好处
死锁的出现必须满足四大条件,互斥条件、请求与保持条件、不可剥夺条件、循环等待条件,预防死锁只要避免其中一个条件就可以了,如按序获取资源、一次申请所有要使用的资源、申请不到资源时,可以放弃已有资源
死锁可以用 jstack 排查
# 线程频繁切换
上下文切换会导致将大量 CPU 时间浪费在寄存器、内核栈以及虚拟内存的保存和恢复上,导致系统整体性能下降。当你发现系统的性能出现明显的下降时候,需要考虑是否发生了大量的线程上下文切换
通过 top 命令以及 top -Hp pid 查看进程和线程CPU情况,发现 Java 线程 CPU 占满了,但是线程CPU使用情况很平均,没有某一个线程把 CPU 吃满的情况,这种情况就是线程频繁切换的典型例子
# 接口变慢了应该如何排查
以上所有问题都会导致接口变慢,所以接口变慢是一个很大很宽泛的问题,为了排查这个问题,我们需要考虑各种情况:
如果是单个接口变慢,可能是该接口涉及到的某个组件出现了问题,我们可以对涉及到的每个方法进行记录,记录每个方法的执行时长,定位到最终问题
如果是多个接口变慢,可能是项目整体出现了问题,涉及到的每个组件都可能是问题源,我们需要先确定范围:
客户端 → 网络 → 负载均衡 → 应用服务器 → 中间件 → 数据库/缓存 → 外部服务
每个范围应该都有对应的报警,如果可以确定是外部报警,就能直接结束排查。如果是中间件、外部服务这些,可以告知下游,我们还可以做一些降级处理
我们需要解决的,是应用服务器、数据库出现慢查这两个范围的问题
如果是服务器问题,可以使用 top、ps、vmstat、jstat 等命令看状态,确认是否 CPU 占满(死循环)、CPU 负载高(使用了不合规的线程池)、内存占满(内存泄漏、频繁生成大对象)、频繁 full gc(堆大小设置太小)等问题
这其中有分两类问题,一是需要调整系统才可以处理的问题(堆大小设置太小),这类问题比较少见,如果出现不建议更改除了堆大小以外的 jvm 参数,建议扩容
第二类是代码问题,我们可以通过线程 ID 找到调用栈,更改对应业务代码处理问题,比如死循环;可以通过 jstat 拉 dump 文件查看内存泄漏、频繁生成大对象等问题
# 频繁 full gc
频繁 full gc 一般会进行报警,我们可以用 jstat 查看 gc 情况
## 1. jstat - 实时GC统计
jstat -gc <pid> 1000 10 ## 每秒1次,共10次
## 关键指标:
## FGC/FGCT:Full GC次数/耗时
## GCT:总GC时间
## 2. jstat -gcutil - 百分比形式
jstat -gcutil <pid> 1000
## 3. 监控输出示例
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 94.44 33.27 87.36 95.77 91.70 2174 65.825 15 9.234 75.059
## ↑ 关注:FGC频率、FGCT时长
2
3
4
5
6
7
8
9
10
11
12
13
同时,在一个系统设计之初,就需要开启 gc 日志,以便发生 gc 问题的时候,快速定位问题
## JVM启动参数
java -Xms2g -Xmx2g \
-XX:+PrintGCDetails \ ## 打印GC详情
-XX:+PrintGCDateStamps \ ## 打印时间戳
-XX:+PrintHeapAtGC \ ## GC前后堆信息
-XX:+PrintTenuringDistribution \ ## 年龄分布
-XX:+PrintGCApplicationStoppedTime \ ## STW时间
-XX:+PrintPromotionFailure \ ## 晋升失败
-Xloggc:/path/to/gc.log \ ## GC日志文件
-XX:+UseGCLogFileRotation \ ## 日志轮转
-XX:NumberOfGCLogFiles=10 \ ## 保留10个文件
-XX:GCLogFileSize=50M \ ## 每个文件50M
-jar your-app.jar
## 或者使用统一的日志框架
-XX:+PrintGC \
-XX:+PrintGCTimeStamps \
-XX:+PrintHeapAtGC \
-XX:+PrintGCApplicationStoppedTime \
-XX:+PrintGCApplicationConcurrentTime \
-XX:+PrintTenuringDistribution \
-XX:+UseGCLogFileRotation \
-XX:NumberOfGCLogFiles=5 \
-XX:GCLogFileSize=10M \
-Xloggc:/var/log/myapp/gc-%t.log
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
这些 gc 日志可以直接看,也可以使用一些图形化分析工具来看,gc 日志一般长下面这样
## GC日志示例分析
2024-01-15T14:23:45.123+0800: 345.678: [Full GC (Ergonomics)
[PSYoungGen: 102400K->0K(204800K)]
[ParOldGen: 409600K->387654K(512000K)] 512000K->387654K(716800K)
, [Metaspace: 65432K->65432K(1060864K)], 1.234567 secs]
[Times: user=3.45 sys=0.12, real=1.23 secs]
## 关键信息:
1. Full GC原因:Ergonomics(自适应调整)
2. 年轻代:102400K → 0K(全部回收)
3. 老年代:409600K → 387654K(回收不多)
4. 元空间:无变化
5. 耗时:1.23秒(STW时间)
2
3
4
5
6
7
8
9
10
11
12
13
看到以上信息后,可以使用 dump 文件,分析堆中内容,看看是否有内存泄漏、本地缓存使用过多的情况
# OOM
oom 一般有以下几种情况:
// 1. Heap Space OOM(最常见)
java.lang.OutOfMemoryError: Java heap space
// 2. GC Overhead Limit Exceeded
java.lang.OutOfMemoryError: GC overhead limit exceeded
// 3. Metaspace OOM(元空间)
java.lang.OutOfMemoryError: Metaspace
// 4. Direct Buffer Memory(直接内存)
java.lang.OutOfMemoryError: Direct buffer memory
// 5. Unable to create new native thread
java.lang.OutOfMemoryError: unable to create new native thread
// 6. Requested array size exceeds VM limit
java.lang.OutOfMemoryError: Requested array size exceeds VM limit
// 7. Out of swap space
java.lang.OutOfMemoryError: Out of swap space
// 8. Kill process or sacrifice child
java.lang.OutOfMemoryError: Kill process or sacrifice child
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
重点是在启动项目时要额外设置参数,不然拿不到错误时的 dump 文件,也就没办法分析了。此外还需要开启 gc 日志
## OOM时自动dump
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/var/log/java_heapdump_%p_%t.hprof
2
3
当 JVM 发生 OOM(OutOfMemoryError)时,JVM 进程本身通常不会直接宕机,但容器可能会被杀掉
JVM 内部的 OOM,比如堆内存 OOM(最常见),抛出 OutOfMemoryError,但JVM 进程本身不会自动退出。后续的内存分配尝试可能会失败,不会直接宕机,但应用程序通常处于不可用状态。理论上可以通过 try-catch 捕获并尝试恢复,但实际上很难,因为堆已满,很难执行有意义的恢复操作
// 典型的堆内存溢出
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
2
OOM Killer 是 Linux 内核在内存耗尽时的紧急制动系统。它通过一个基于内存使用量和可调优先级的评分机制来选择牺牲品。对于系统管理员和开发者,理解其原理并合理设置关键进程的 oom_score_adj,或使用更先进的 cgroups 进行内存隔离,是保证系统稳定性的重要手段
我之前遇到过日志打的太多导致 OOM 了,因为大量日志导致堆外内存溢出